

들어가며
정산시스템은 삼쩜삼에서 제공하는 모든 서비스들의 결제내역 및 신고(세금신고) 여부에 따라 회사의 매출을 계산할 수 있도록 지원하는 시스템입니다. 이러한 정산시스템의 목적상 각 서비스별로 일별 배치작업을 통해 결제, 신고, 취소 등의 모든 데이터를 수집하고 있습니다.
정산시스템을 제일 많이 활용하는 재무팀에서는 매월을 기준으로 각 서비스별 매출에 대한 계산이 필요하며, 이를 회계적 증빙 등의 자료로 활용하기 위해 엑셀 데이터를 별도로 관리하는 작업도 수행하고 있습니다. 이는 단순 시스템에서의 페이징 조회 작업뿐만 아니라 특정 일자 기준의 데이터를 엑셀로 다운받을 수 있도록 제공해야 하는 목적도 함께 가지고 있습니다.
배치작업을 통해 수집되는 데이터는 매년 정기 종합소득세 신고 기간인 5월 기준으로는 한 달 약 500만 건 이상의 데이터가 수집되고 있습니다. 문제는 이러한 특정 일자 단위의 엑셀 데이터 다운로드에서 존재하는 데이터 분포의 불균일성입니다.
실제 결제/신고/취소 내역이 많은 5월의 경우 해당 월의 데이터를 엑셀로 출력하는 경우 서버로부터 OOM(Out Of Memory)이 발생하는 상황이 빈번했으며, 이는 해당 월의 데이터가 필요한 재무팀의 업무에 지연을 불러오고 전반적인 상황 모니터링을 해야 하는 5월 특성상 에러 채널에서 신경을 분산시키는 문제가 있었습니다. 이번 글에서는 이처럼 많은 데이터의 엑셀을 다운로드하는 경우 발생하는 OOM 문제에 대한 해결 과정을 공유합니다.
OOM(Out Of Memory) 발생
정기 종합소득세 신고 기간으로 바쁜 5월, 모니터링 중이던 Slack의 Error 채널에 정산시스템 관련 에러가 발생합니다.
정산시스템은 대고객 서비스와 같이 트래픽이 많은 서비스도 아니며, 정산을 수행하는 재무팀도 정산 기간 이외에는 많이 접근하지 않는 시스템이므로, 집중이 필요한 5월에 더 큰 우선순위를 두기 위해 해당 데이터를 DB에서 직접 추출하여 전달하는 방식을 선택했습니다.
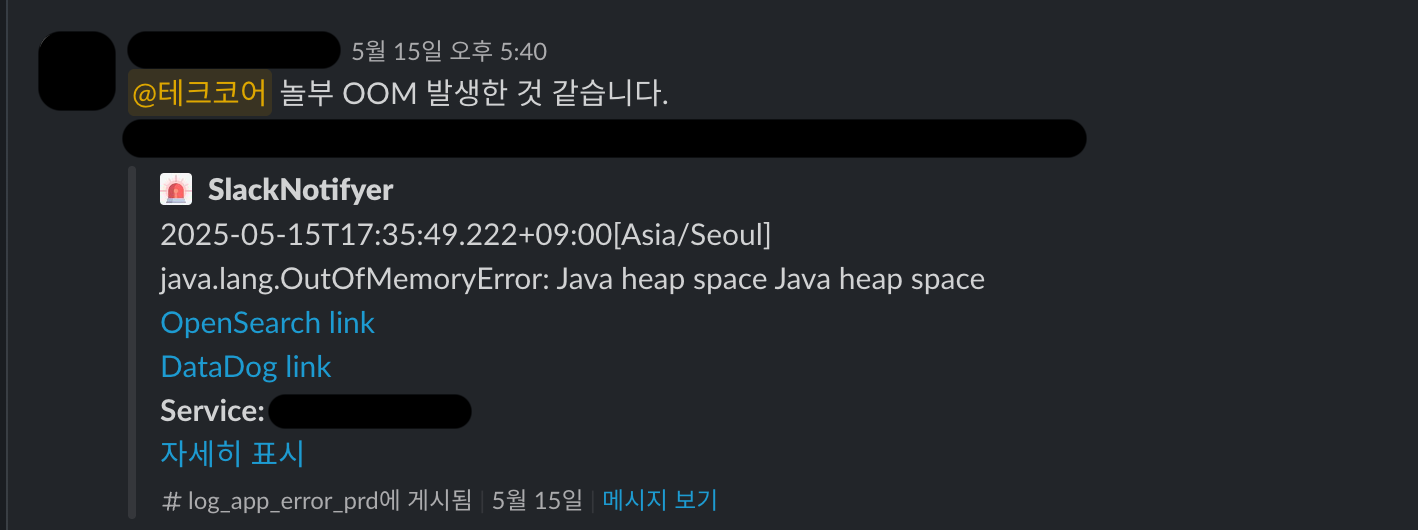
문제는 이러한 오류가 5월이 끝난 6월, 다른 곳에서 발생했다는 점입니다. 이 역시 출력할 데이터의 내용은 다르지만 동일하게 엑셀 출력 부분에서 발생했다는 점이 가장 큰 문제였습니다.
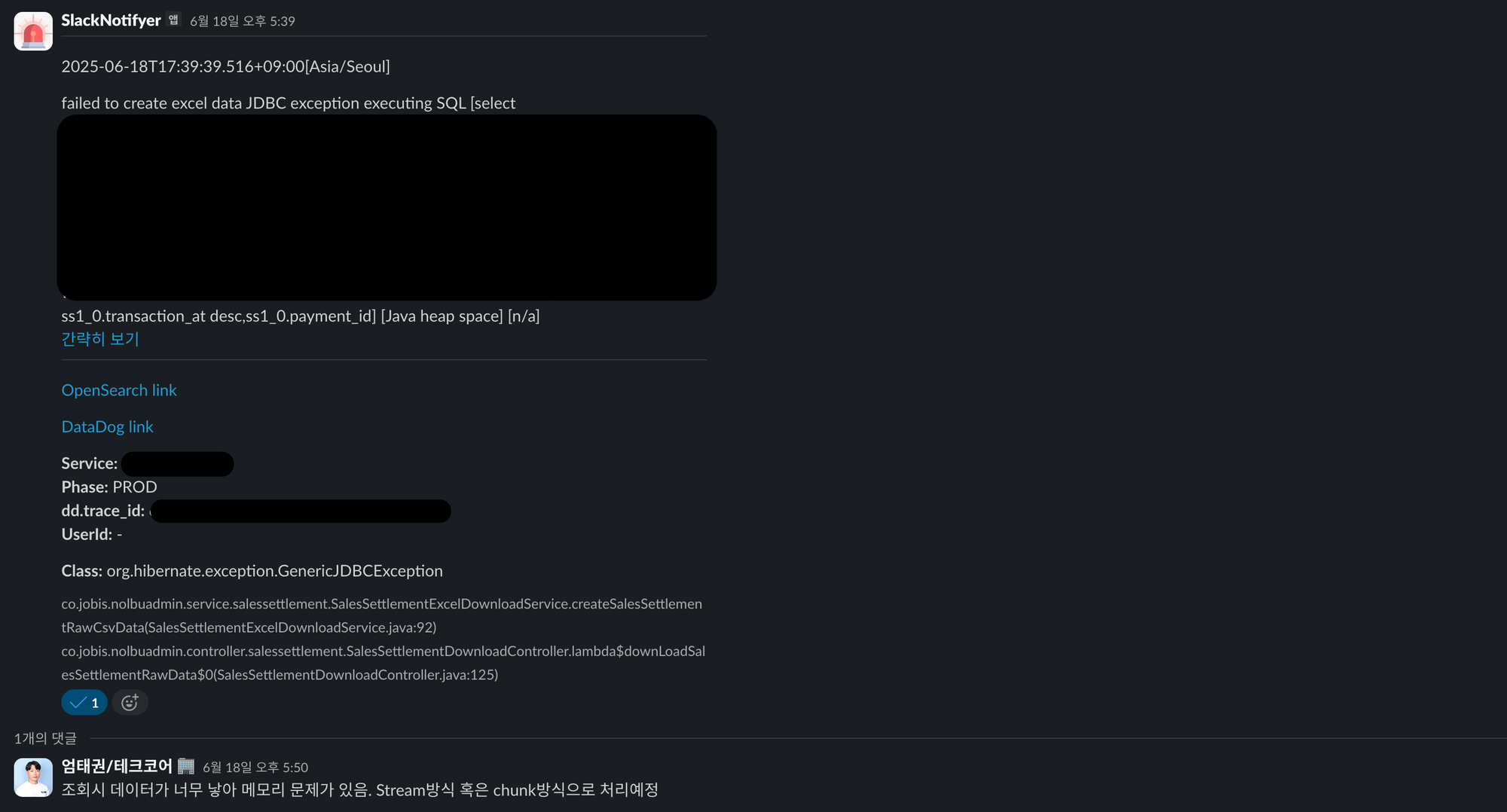
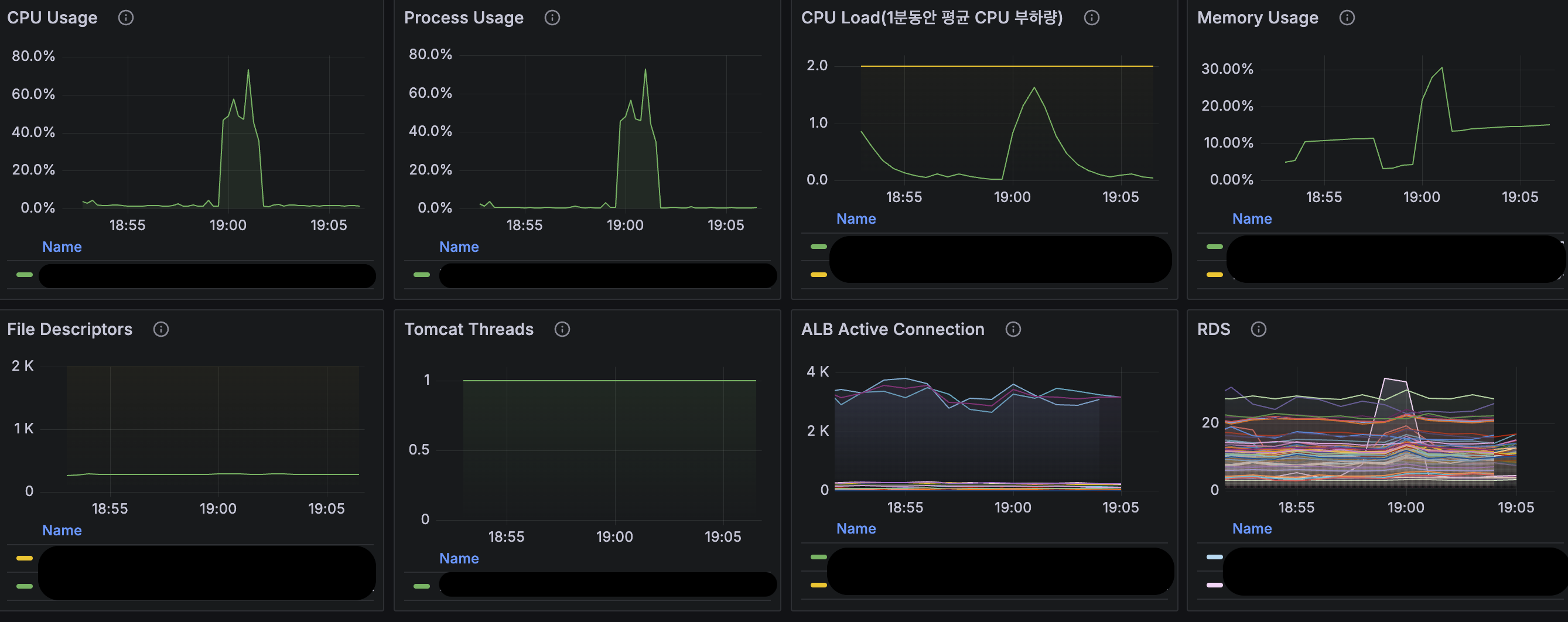
또한 해당 시점에서의 모니터링 툴인 Grafana의 지표를 보면 아래와 같이 CPU, Memory 사용량과 RDS의 CPU사용량이 100%에 도달하는 것을 볼 수 있습니다.
OOM이 발생한 원인 파악
불균형한 데이터 분포의 날짜 조회
정확한 원인 분석을 위해 해당 에러가 발생한 메서드를 추적하면 아래와 같습니다.
Class: org.hibernate.exception.GenericJDBCException
co.jobis.nolbuadmin.service.salessettlement.SalesSettlementExcelDownloadService.createSalesSettlementRawCsvData(SalesSettlementExcelDownloadService.java:92)
co.jobis.nolbuadmin.controller.salessettlement.SalesSettlementDownloadController.lambda$downLoadSalesSettlementRawData$0(SalesSettlementDownloadController.java:125)실제 해당 메소드의 수행 부분을 보면 아래와 같은 단순한 방식의 엑셀 처리 로직입니다.
@Transactional(readOnly = true)
public ExcelRender createSalesSettlementRawData(SalesSettlementReconciliationRequest request) {
List<SalesSettlementExcelData> salesSettlementExcelData = salesSettlementRepository.findAllBySettlementClassifier(request).stream()
.map(SalesSettlementExcelData::of)
.toList();
SXSSFExcelFile excelFile = new SXSSFExcelFile(salesSettlementExcelData);
String fileName = String.format("%s_sales_settlement_raw", LocalDate.now().format(EXCEL_DATE_FORMATTER));
excelFile.generateFileName(fileName);
return excelFile;
}이때 사용자(재무팀)의 요청 파라미터는 아래와 같이 여러 개의 필터 조건으로 검색할 수 있도록 구성되어 있습니다.
public record SalesSettlementReconciliationRequest(
@Schema(description = "요청 시작일")
LocalDate requestStartDate,
@Schema(description = "요청 종료일")
LocalDate requestEndDate,
@Schema(description = "신고 시작일")
LocalDate submitStartDate,
@Schema(description = "신고 종료일")
LocalDate submitEndDate,
@Schema(description = "PG 타입")
PgType pgType,
@Schema(description = "결제 수단")
PayMethod payMethodType,
@Schema(description = "서비스 타입")
ServiceType serviceType,
@Schema(description = "신고 타입")
SubmitType submitType,
@Schema(description = "거래상태 타입")
DisplayTransactionType transactionType
) {}문제는 해당 상황에서 사용자의 요청 파라미터 중 요청 시작일과 요청 종료일에 있습니다. 당시 재무팀은 작년 그리고 올해 5월의 데이터를 출력하길 원하는 상태였고, 이때의 요청값에 해당하는 DB 데이터의 Row 수는 각각 약 500만 건 이상의 데이터입니다.
대량의 데이터 조회는 아래 두 가지 경우에 발생하며, 이러한 상황은 이후에 발생하는 문제들의 직접적인 영향을 주는 문제입니다.
2. 조회 기간에 데이터가 많은 5월이 포함되는 경우
대용량 데이터 엑셀 출력으로 인한 메모리 부족
현재 정산시스템에서 엑셀다운로드시 처리되는 데이터의 Class를 보면 아래와 같습니다.
public record SalesSettlementExcelData(
String taxformId,
String paymentId,
String orderNo,
String payNo,
LocalDateTime transactionAt,
LocalDateTime paidAt,
LocalDateTime canceledAt,
LocalDateTime submitReportedAt,
String transactionType,
String pg,
String payMethod,
String payMethodDetail,
String serviceType,
String submitType,
String year,
String submitReportNo,
String cancelType,
BigDecimal taxformTransactionAmount,
BigDecimal taxformFeeAmount,
BigDecimal taxformVatAmount,
BigDecimal taxformSaleAmount,
BigDecimal scroogeOrderTransactionAmount,
BigDecimal pgOrderTransactionAmount,
BigDecimal differenceOrderTransactionAmount
) { }단순 각 필드별 메모리를 대략 평균값으로 계산해 본 경우 해당 객체 하나의 메모리 사이즈는 약 1.5KB입니다. 이는 String Type의 길이에 따라 2.5KB까지 늘어날 수 있습니다. 해당 메모리 사이즈는 객체의 헤더 등 JVM 레벨의 Overhead를 제외한 수치입니다.
만일 100만 건의 데이터를 엑셀 다운로드 하는 경우 순수 데이터 객체의 사이즈만 1.5GB에 해당합니다. 계산식에서 제외된 다른 모든 요건을 고려하면 약 2GB가 넘어가는 정도의 사이즈로 이는 2 vCpu / 4GB의 제한된 리소스를 사용하는 정산시스템에게는 50%에 해당하며 5월처럼 많은 데이터가 존재하는 경우 메모리 사이즈는 8GB 이상을 차지하게 됩니다.
또한 해당 데이터들을 모두 읽어와 엑셀을 출력하는 코드에도 문제가 있습니다. 정산시스템은 엑셀 출력 시 apache-poi를 사용 중입니다. 이때 많은 엑셀 코드 작업을 편리하게 하기 위해 내부적으로 엑셀 생성을 하는 Render를 만들어 수행하며, 실제 반복되는 Rendering 코드를 매번 작성하지 않도록 편의성을 제공하고 있습니다.
이때 출력해야 할 데이터 객체를 파싱하며 엑셀의 row에 출력하는 부분의 코드 중 Reflection을 사용하는 코드가 존재하며 해당 코드는 대상 데이터의 사이즈만큼 반복 수행됩니다. 이러한 Reflection은 실제 서버 CPU에 큰 부담을 주고 있습니다. 그 외 문자열 변환 및 포맷팅 등의 작업 또한 마찬가지입니다.
private void renderFieldsFromObject(Row row, int startColumnIndex, Object targetObject) {
try {
Field[] fields = targetObject.getClass().getDeclaredFields();
int columnIndex = startColumnIndex;
for (Field field : fields) {
field.setAccessible(true);
Object value = field.get(targetObject);
Cell cell = row.createCell(columnIndex++);
renderCellValue(cell, value);
}
} catch (Exception e) {
log.error("[ExcelFileRender] renderFieldsFromObject: error occurred while rendering fields", e);
throw ExcelRenderException.thrown("Error occurred while rendering fields");
}
}이러한 요인들이 위의 Grafana 모니터링에서 보이듯이 CPU, 메모리 모두 100%에 도달하며, 결국 모든 리소스를 소진한 정산시스템은 Unhealthy한 상태로 해당 Task에 대한 재기동이 수행됩니다.
재시도 요청에 따른 부가적 문제
현재 정산시스템을 비롯한 삼쩜삼의 내부 시스템(이하 백오피스)은 BackOffice Gateway를 통해 권한체크 및 요청 Path에 따른 Routing을 하도록 구성되어 있습니다.
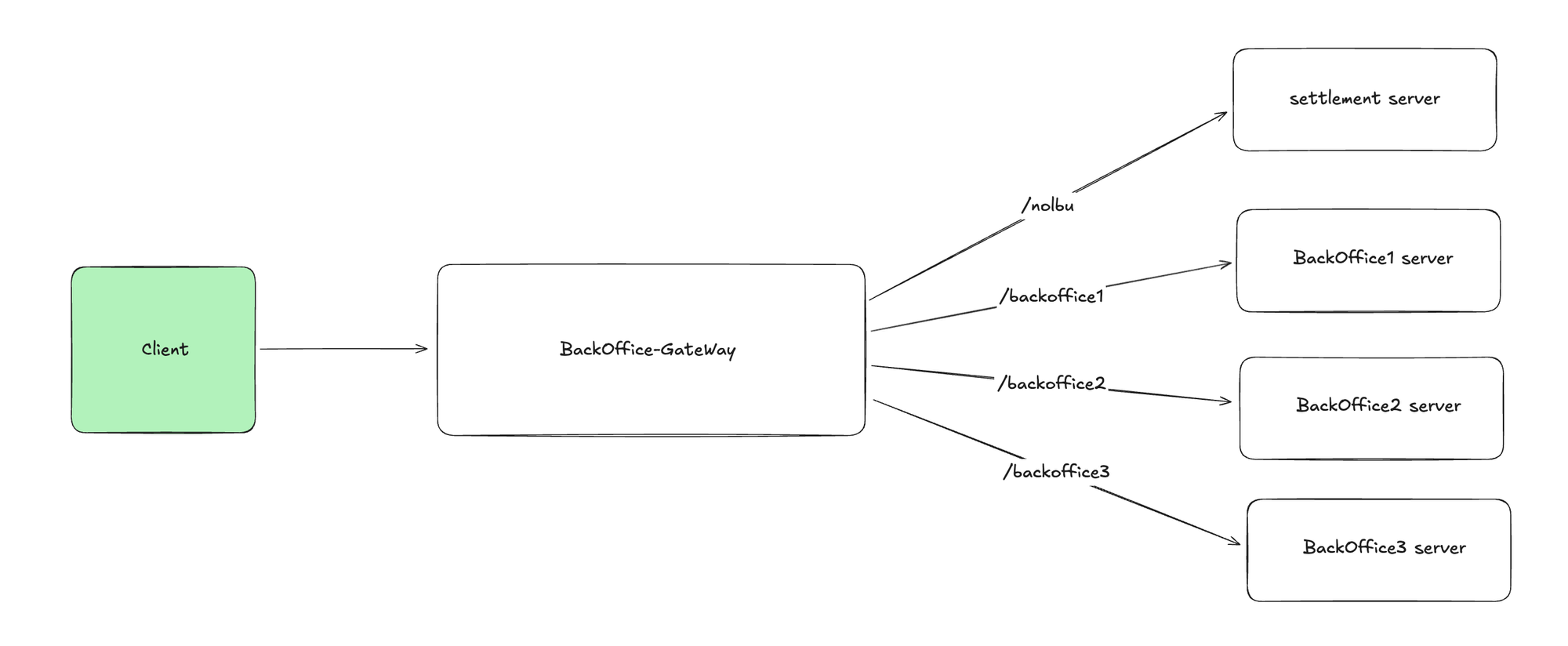
이때 BackOffice Gateway는 Client의 요청에 대한 응답을 서버로부터 받지 못하는 상황이 발생할 경우 재시도 정책을 가지고 있으며, 2번까지의 재시도를 수행하도록 되어 있습니다. 이때 ResourceAccessException이 발생 시에만 재시도하게 되어 있으며, 이는 서버와의 네트워크 통신 실패, Timeout 혹은 IOException 등의 문제가 있을 경우 수행됩니다.
@Bean
public RouterFunction<ServerResponse> routerFunction() {
RouterFunction<ServerResponse> routerFunction = null;
for (RouteProperties routeProperties : gatewayProperties.routes()) {
RouterFunction<ServerResponse> router = route(routeProperties.id())
// 중략
.filter(retry(config -> config
.setRetries(2)
.setSeries(Set.of())
.setMethods(Set.of())
.setExceptions(Set.of(ResourceAccessException.class))
))
.after(logResponse())
.after(removeResponseHeaders())
.build();이러한 재시도 처리 방식은 Client의 입장에서 일시적 장애에 대한 복원 등 사용자 경험을 개선할 수 있는 좋은 정책이지만, 엑셀 다운로드 요청의 경우 오히려 출력을 수행해야 하는 정산시스템의 입장에서는 큰 부담으로 작용합니다. 이는 아래와 같은 상황을 예로 들 수 있습니다.
먼저, 클라이언트는 정산시스템에 5월 데이터에 대한 엑셀 데이터 출력을 요청합니다. 이때 해당 요청은 BackOffice Gateway로 전달되며, 이는 Path(/nolbu)를 통해 정산시스템에 요청이 라우팅되게 됩니다.
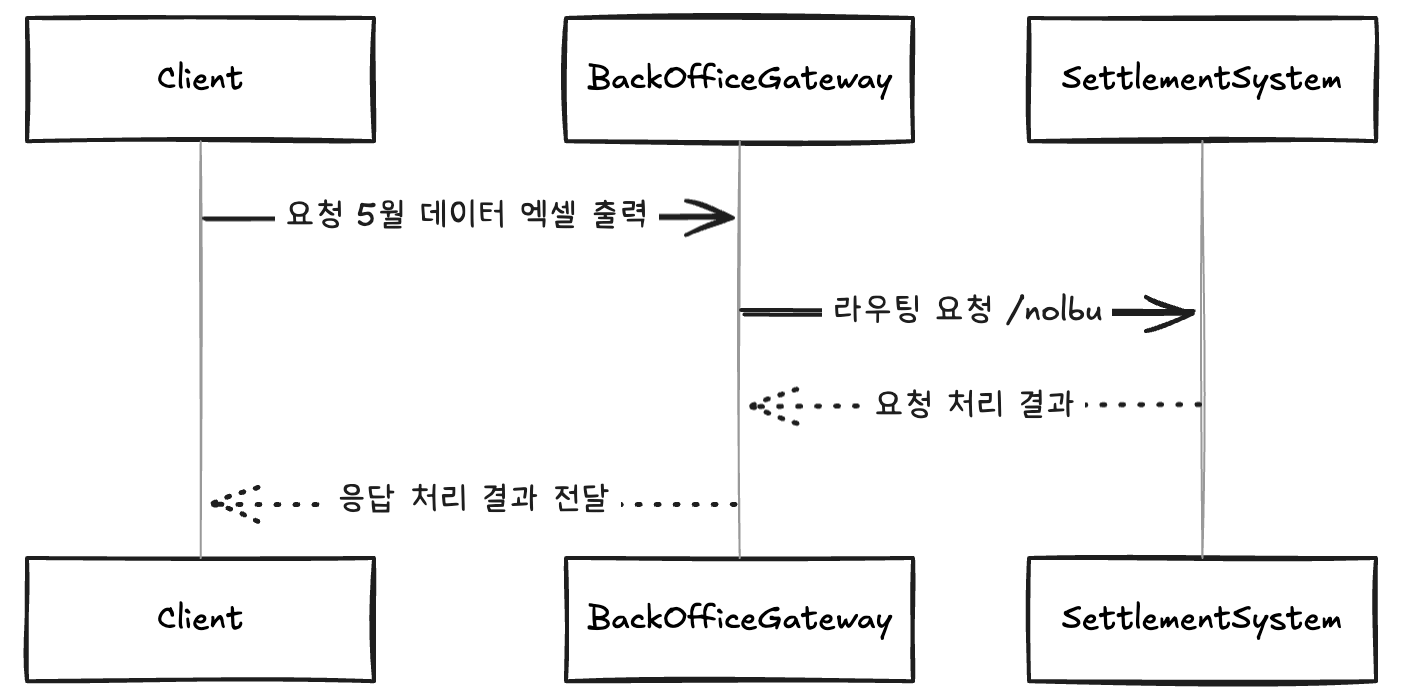
이때 정산시스템은 요청 기간에 해당하는 데이터를 DB로부터 조회하며 데이터는 약 500만 건 이상입니다. 정산시스템은 해당 데이터들을 위의 코드와 같이 메모리에 올려놓고 엑셀에 출력하는 서비스 로직을 수행합니다. 이를 엑셀로 출력하여 클라이언트에게 엑셀로 전달하기까지 긴 시간이 소요되며, 이는 BackOffice Gateway에서 지정한 ReadTimeout 시간(5초)을 훨씬 넘는 시간입니다.
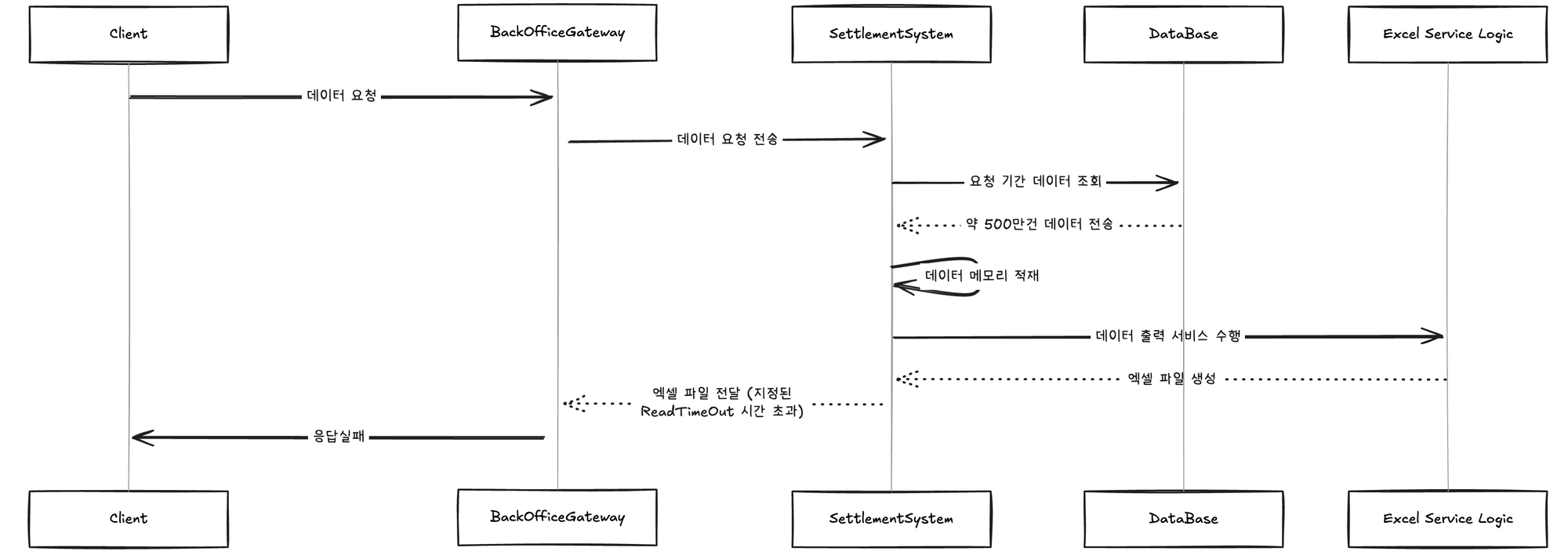
ReadTimeout 시간을 초과하면서 결국 BackOffice Gateway는 ResourceAccessException이 발생하게 되고, 이를 설정해둔 필터 조건에 맞춰 2번의 재시도를 수행하게 됩니다. 재시도를 수행할 때마다 결국 같은 상황으로 최종적으로 Client는 엑셀 출력에 대한 응답을 받지 못하게 되며 정산시스템은 해당 요청을 기준으로 초기 요청까지 총 3번의 동일한 요청을 DB로 전달하고 전달받은 데이터 모두를 메모리에 올려놓고 작업하는 상황이 발생합니다.
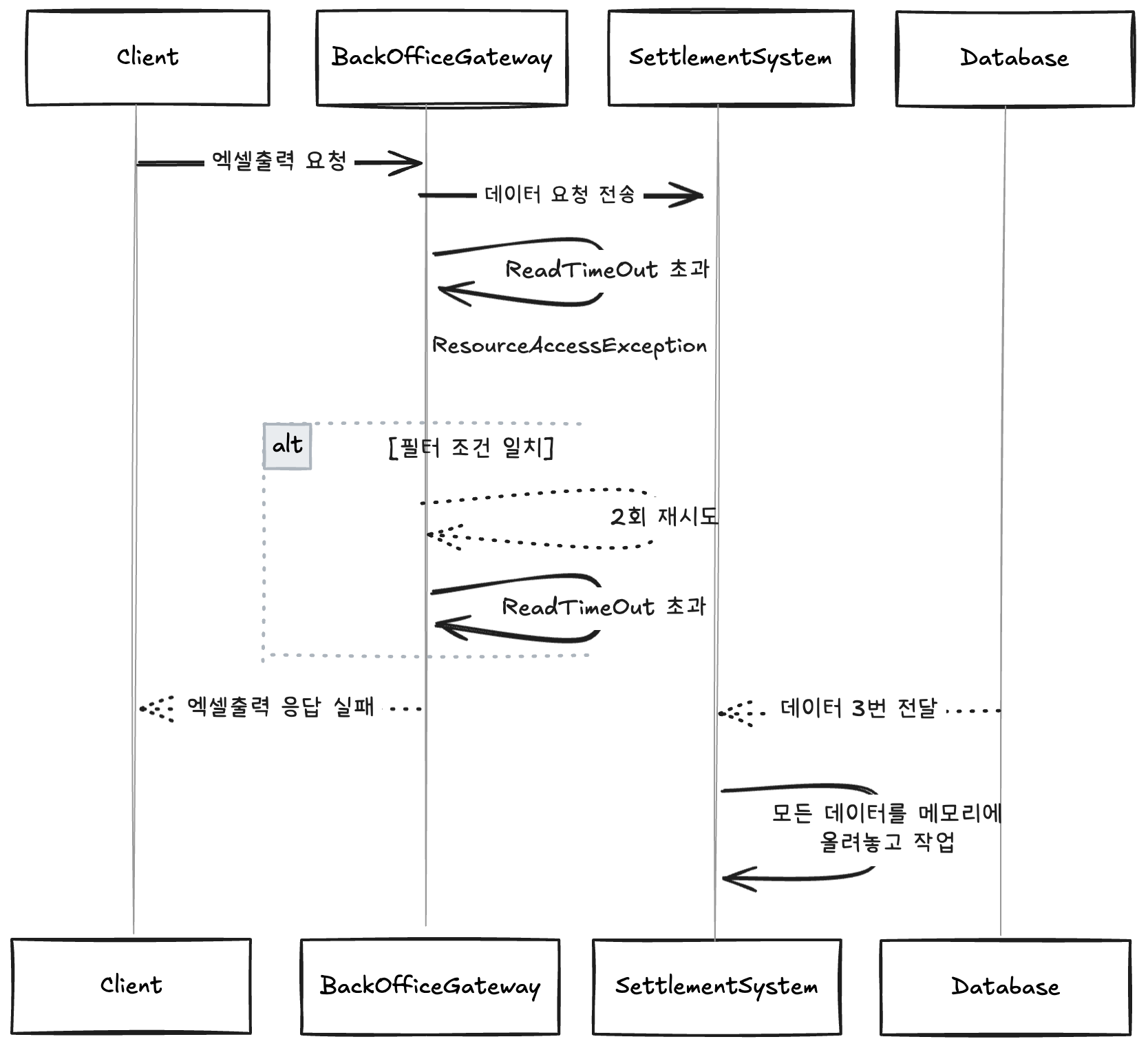
문제는 하나의 대용량 엑셀 데이터를 출력하기에도 버거운 정산시스템에게 이러한 대규모 엑셀 출력 재시도 요청은 정산시스템의 리소스에 부담이 된다는 것입니다. 단순한 SELECT * FROM DATA WHERE …과 같은 쿼리의 경우 조회된 데이터들이 엑셀 출력을 위해 메모리에 적재되면서 발생하는 추가적인 메모리 리소스 고갈 문제를 유발하며, 복잡한 JOIN, GROUP BY 혹은 SUM() 등의 함수들은 반복적인 복잡한 쿼리 요청으로 위 그라파나의 예시와 같이 RDB의 CPU 리소스 증가를 유발합니다.
이러한 문제를 해결하기 위해 BackOffice Gateway의 재시도 정책을 막는다거나 ReadTimeout 시간을 늘리는 것은 정산시스템이라는 특정 서비스의 엑셀 다운로드라는 특정 기능이 전반적인 BackOffice 정책에 영향을 주는 상황으로 보다 근본적인 해결 방법이 필요합니다. 또한 재시도를 막는 정책은 사용자의 경험과 시스템의 가용성, 신뢰성을 오히려 저하시키는 원인이 될 수 있습니다.
문제해결 방법 구상
위에서 언급한 내용처럼 BackOffice Gateway의 설정을 바꾸거나 하는 수정방식은 정산시스템의 문제를 외부에서 해결하는 것으로 근본적 해결 방법이 아니었습니다. 또한 현재의 리소스에서 가능한 최대한을 활용하여 문제를 해결는것이 목표였습니다. 따라서 몇가지 실현가능한 방법들을 고민했으며, 이는 각각 아래와 같습니다.
- 시스템 리소스 ScaleUp
- 엑셀출력의 데이터 조회 기간 제어
- On-Demand 배치 처리
- Chunk 혹은 날짜 단위의 병렬 처리
시스템 리소스 ScaleUp
가장 먼저 생각한 방식은 시스템 리소스의 ScaleUp이었습니다. 이는 당시 빠른 처리를 위해 생각한 단순한 해결 방식이었습니다. 장점으로는 가장 쉬운 방식으로 단순 실행되는 Task의 리소스만 증가하면 되는 해결방법입니다. 하지만 아래와 같은 사유로 해당 방법은 진행하지 않았습니다.
가장 먼저 리소스 증가가 모든 문제를 해결해 주지 않는다는 점이 있습니다. 이는 데이터가 많아지면 많아질수록 더 많은 리소스가 필요해진다는 점이 문제였습니다. 또한 위에서 발생한 BackOffice Gateway의 재시도와 같은 상황에선 더 많은 서버 리소스가 필요하게 됩니다.
다음으론 비용문제 입니다. 정산시스템은 특성상 재무팀과 같이 관련있는 팀만 접근하는 시스템으로 TPS가 매우 낮은 내부 시스템입니다. 엑셀 다운로드 기능 또한 정산을 수행하는 시즌(월 초)을 제외하면 그렇게 많은 요청이 수행되지 않는 다는 특징이 있습니다. 이처럼 특정 기능을 위해 평상시에는 문제없이 동작하던 시스템 리소스를 증가하는 것이 비용적으로 맞는지도 의문이었습니다.
엑셀출력의 데이터 조회기간 제어
다음으로 생각한 방법은 엑셀출력의 데이터 조회기간을 제어하는 방법입니다. 이는 타 정산시스템에서도 사용하고 있는 방법으로 조회의 기간을 제어하는 방식입니다. 이 또한 쉬운 방법으로 Front-End 및 Server에서 기간만 제어하면 되는 간단한 방법입니다.
예를 들어 조회 기간이 한 달을 넘지 않도록 시스템에서 제어한다면, 사용자는 해당 되는 기간의 데이터만 조회하거나 엑셀출력이 가능한 방식으로, 삼쩜삼의 정산시스템 같은 경우 5월의 데이터의 특성을 고려하여 한 달이아닌 3일 혹은 5일 등의 일자별 제한을 두는 것이었습니다.
long days = ChronoUnit.DAYS.between(requestStartDate, requestEndDate);
if (days > 5) {
throw new IllegalArgumentException("요청일 범위는 최대 5일까지만 조회할 수 있습니다.");
}하지만 이런 방식은 데이터가 더 많아질수록 유동적으로 변동되어야 하며, 그 수치는 경험에 기반한 것으로 한 번에 예측하여 나누기 쉽지 않습니다. 또한 이는 문제의 범위를 축소시켜서 해결하는 방식으로, 이보다는 근본적인 문제를 타파할 수 있는 방법을 도입하고 싶었습니다.
On-Demand 배치 처리
일반적으로 배치(Batch) 작업은 정해진 스케줄에 따라 자동으로 동작합니다. 하지만 주기적으로 실행될 필요가 없는 업무가 있으며 특정 시점에만 데이터를 처리하거나, 사용자가 직접 요청시에만 수행되는 배치작업이 필요한 경우가 있습니다. 이런 형태를 On-Demand 형태의 배치 처리라고 합니다.
현재 정산시스템은 정산데이터 수집 및 통계를 위한 별도의 Batch프로세스를 수행하고 있으며, Batch작업을 수행하기 위한 인프라 환경도 구축되어 있는 상태입니다. On-Demand 배치 처리방식은 현재 구조에 적용하기 적합한 작업이었으며, Spring Batch의 대용량 데이터 처리에 효율적인 특성 또한 맞아 떨어졌습니다. 또한 실제 작업은 Batch서버에서 수행되기 때문에 이전과 같은 정산시스템의 OOM 및 CPU의 부하도 줄여줄 수 있습니다.
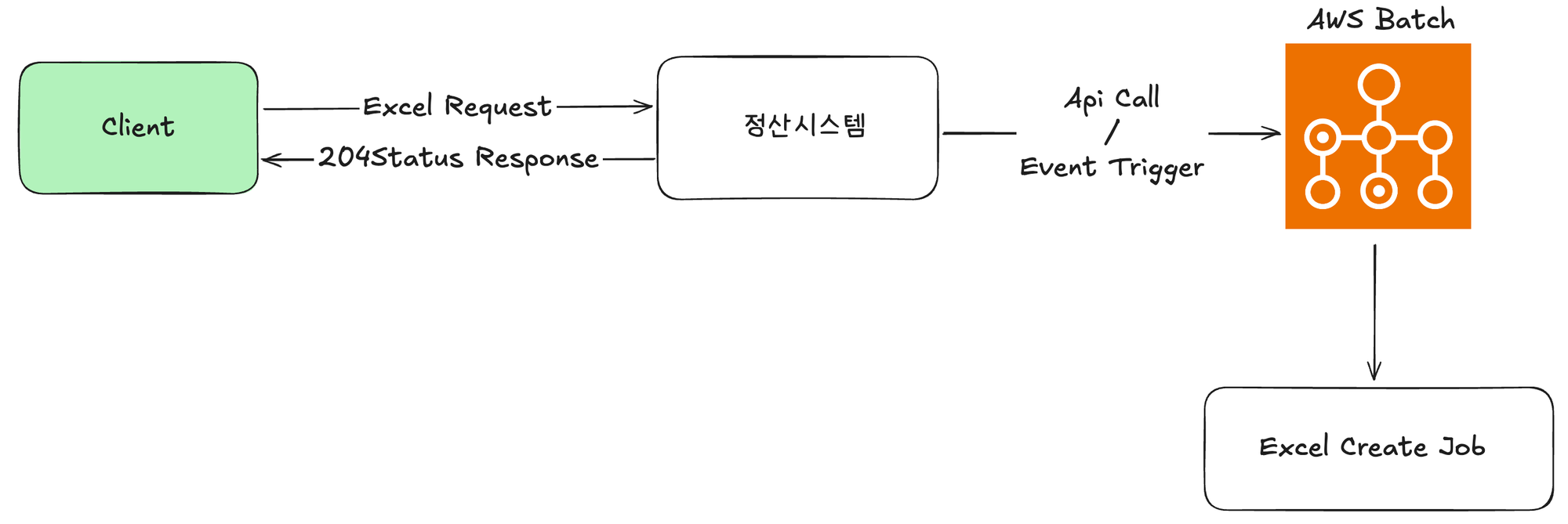
하지만 매 실행마다 Batch서버 기동이 필요한점과 Job 구성에 대한 로딩이 필요하여 호출과 실행 자체가 가볍진 않다는 점, 이미 실행되고 있는 엑셀 출력 Job이 있다면 동일한 파라미터 구조로 다시 실행하기 어렵다는점이 단점입니다. 또한 실행시 발생하는 에러 로그에 대해 분산되어 있어 두 서버(정산시스템, Batch)의 로그를 봐야한다는 불편함이 있습니다.
Chunk 단위의 병렬 프로세스 처리
문제해결 방법중 하나였던 On-Demand 배치 처리 방식의 정산시스템과의 분리된 프로세스 처리 방식과 Chunk단위의 처리 방식은 분명 문제였던 OOM 및 CPU부하를 해결할 수 있는 방법이었습니다. 이에, 이런 좋은 부분을 활용하여 최종적으로 정산시스템 자체에서 Chunk 혹은 일자 단위로 병렬처리하는 방법의 도입을 고민했습니다.
대량의 데이터를 적절한 단위(개수 혹은 조회날짜)로 쪼갠 후 메모리에 해당 데이터들을 모두 올려놓고 작업하지 않도록 병렬 프로그래밍을 활용한다면 이론적으로 서버의 ScaleUp, 조회 날짜제한없이 대용량 데이터 엑셀처리를 할 수 있다는 생각이 들었습니다.
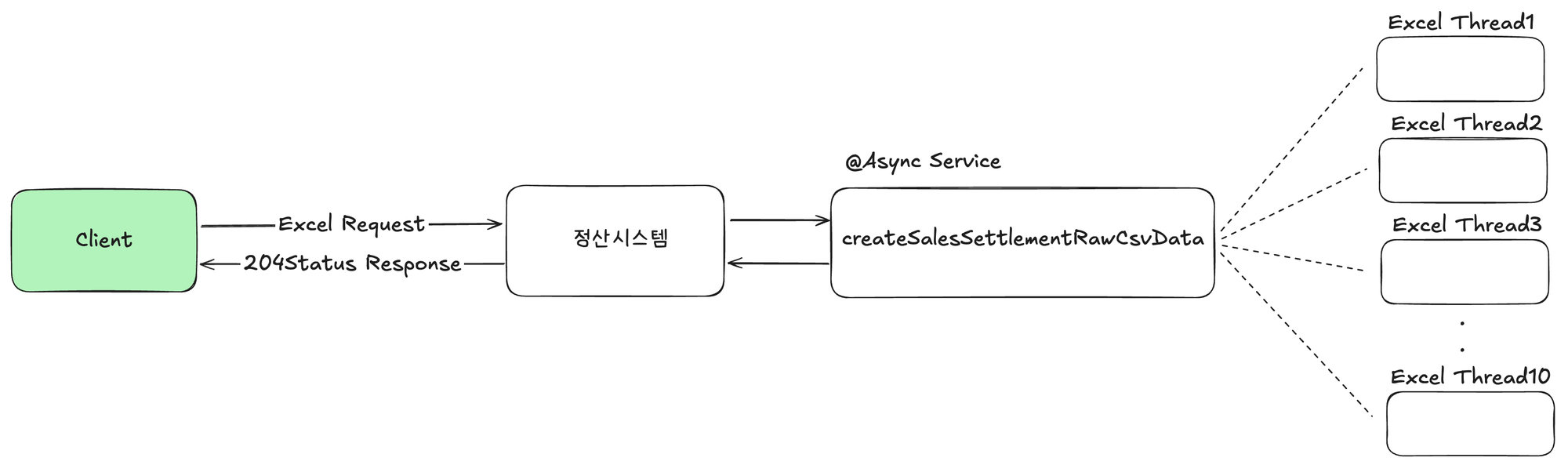
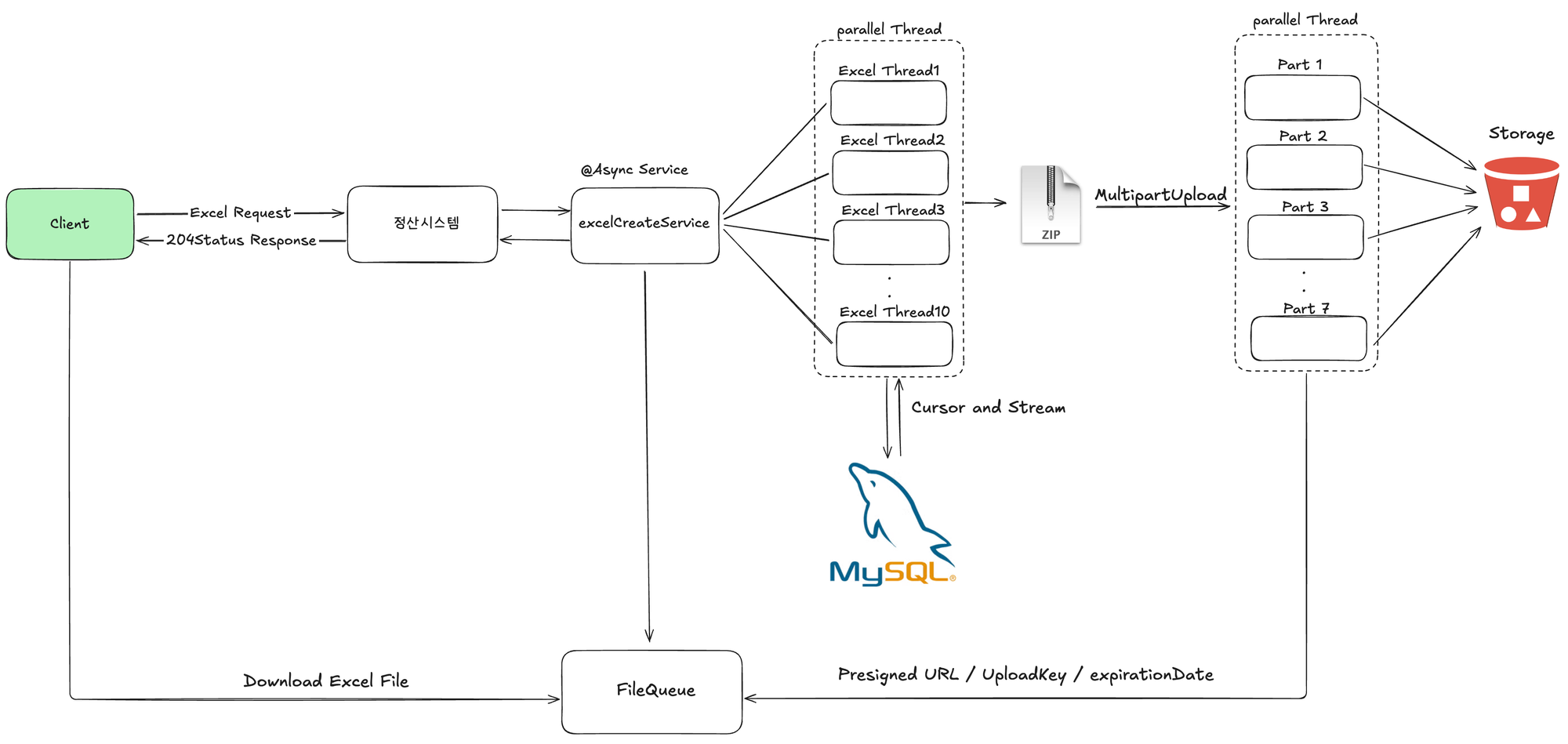
이러한 방식은 최종적으로 사용자에게는 엑셀 다운로드 요청 후 파일대기열등을 통해 진행상황을 확인하고 다운로드하는 비동기적인 프로세스로 변경이 필요합니다. 이는 동기적인 방식에서 응답이 오래걸려 재시도 정책으로 인해 발생하던 부가적인 문제도 엑셀 다운로드 요청완료 응답을 통해 해결이 가능합니다.
최종적으로 해당 방식은 시스템 리소스를 증가시키지 않고도 대용량 데이터를 처리할 수 있어, 평상시 사용량이 적은 정산시스템에 불필요한 비용이 발생하지 않습니다. 또한 조회 기간 제한 없이 원하는 데이터를 자유롭게 조회할 수 있으며, 데이터가 증가해도 유연하게 대응 가능한 확장성을 확보할 수 있다는 생각이었습니다. 이러한 이유로 정산시스템은 최종적으로 Chunk 단위의 병렬 프로세스 처리 방식을 선택하게 되었습니다.
해결과정
날짜단위의 작은 병렬조회
기존의 엑셀 데이터 조회 방식은 한 번에 많은 범위의 날짜를 쿼리의 조건에 넣는 방식이었습니다. 이는 많은 데이터를 한 번에 메모리에 올려놓고 작업해야 하기 때문에 메모리에 큰 부담을 주는 방식입니다. 또한 순차적인 엑셀 Row 작성으로 엑셀 생성에 많은 시간이 걸립니다. 이를 해결하기 위해 우선 특정 일 수 단위로 작게 조회하는 방식을 먼저 적용하기로 했습니다.
먼저, 재무팀을 통해 3일치 데이터의 경우 출력이 가능했다는 경험 기반의 데이터를 통해 3일 단위로 엑셀 출력을 나누는 전략을 선택했습니다. 예를 들어 2025-05-01 ~ 2025-05-31까지의 데이터가 들어오는 경우 3일 단위씩 쪼개어 DB 조회를 수행하는 방식입니다.
위와 같이 한 달 단위의 데이터를 조회하는 경우, 모든 데이터를 조회하는 병렬 프로세스가 10개 ~ 11개가 필요합니다. 이러한 수치를 활용해 병렬 작업을 수행하기 위한 Executor 설정이 가능합니다. 다만 엑셀을 생성하는 단계에서 CPU 소모가 불가피하기 때문에 이를 고려해 설정했습니다.
@EnableAsync
@Configuration
public class AsyncExecutorConfig {
@Bean(name = "excelMonthlyReportExecutor")
public Executor excelMonthlyReportExecutor() {
ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor();
taskExecutor.setCorePoolSize(5);
taskExecutor.setMaxPoolSize(11);
taskExecutor.setQueueCapacity(10);
taskExecutor.setThreadNamePrefix("excelMonthlyReportExecutor-");
taskExecutor.setWaitForTasksToCompleteOnShutdown(true);
taskExecutor.setAwaitTerminationSeconds(30);
taskExecutor.setTaskDecorator(new RequestContextTaskDecorator());
return taskExecutor;
}이렇게 날짜 단위로 작은 병렬 처리를 수행하는 경우, DB에 조회해야 할 데이터의 범위를 축소시켜 줄 수 있으며, 이는 DB의 조회 속도를 향상시켜줍니다. 또한 설정한 스레드가 모두 병렬적으로 3일 단위로 나누어진 범위를 조회하며, 각자가 병렬적으로 엑셀을 작성한다면 생성 시간 또한 크게 줄어들 것으로 기대했습니다.
하지만 아직 메모리 리소스에 대한 부하는 해결하지 못했습니다. 조회 범위를 쪼개어 병렬 처리를 수행하더라도 각 스레드가 조회한 데이터들은 모두 메모리에 올려놓고 작업을 하기 때문에 전체적으로 사용하는 메모리의 양은 기존과 바뀐 것이 없습니다.
엑셀 데이터 조회 방식의 변경
기존 엑셀 출력시 DB를 통해 출력대상 데이터를 조회하는 코드는 아래와 같습니다.
public List<SalesSettlementRaw> findAllBySettlementClassifier(SalesSettlementReconciliationRequest request) {
JPAQuery<SalesSettlementRaw> query = createSettlementRawFetchQuery(request)
.orderBy(
SALES_SETTLEMENT.transactionAt.desc(),
SALES_SETTLEMENT.paymentId.asc());
return query.fetch();
}여기서 주목해야할 부분은 query.fetch() 부분으로 해당 메소드의 실행을 좀 더 깊게 보면 아래와 최종적으로 아래와 같이 모든 조회 데이터를을 List에 담아 처리하는 것을 볼 수 있습니다.
/**
* ListResultsConsumer.consume()
*/
public List<R> consume(...) {
Results<R> results = new Results<R>(domainResultJavaType);
while(rowProcessingState.next()) {
results.add(
rowReader.readRow(rowProcessingState, processingOptions)
);
rowProcessingState.finishRowProcessing(true);
++readRows;
}
return results.getResults();
}
/**
* Results Inner Class
*/
private static class Results<R> {
private final List<R> results = new ArrayList();
public void add(R result) {
this.results.add(result);
}
public List<R> getResults() {
return this.results;
}
}위와 같은 동작 방식은 모든 조회 결과를 List로 담아두고 작업하기에 날짜 단위로 쪼개어 병렬로 작업을 처리해도 각 스레드들이 조회한 결과값을 메모리에 올려놓고 작업하기 때문에 동일한 OOM 문제가 발생할 수 있습니다. 이러한 문제를 해결하기 위해서는 조회한 데이터를 모두 메모리에 올려놓지 않고 작업할 수 있는 Stream 처리 방식의 처리가 필요했습니다.
초기 해당 문제를 해결하기 위해 단순 반환값을 Stream 타입으로 처리한다면 가능하지 않을까 하는 생각을 했으며, 이를 적용하기 위해 기존 query.fetch() 메서드가 아닌 query.stream()을 선택했습니다. 하지만 해당 메서드의 실제 동작 방식을 확인해 보면 아래와 같은 코드에 도달합니다.
package jakarta.persistence;
public interface Query {
List getResultList();
default Stream getResultStream() {
return this.getResultList().stream();
}결국 이는 getResultList()를 통해 조회한 모든 데이터 List를 Stream 타입으로 변환하는 코드에 불과한 작업이었습니다. 해당 방향으로는 메모리 문제를 해결할 수 없었고 최종적으로 정산시스템은 Stream을 활용한 데이터 처리와 Cursor 기반의 DB 조회를 선택했습니다.
Cursor 기반의 조회 방식은 대용량 데이터를 메모리 효율적으로 처리하기에 적합합니다. 우리가 흔히 사용하는 일반적인 SELECT문의 경우, 즉시 전체 결과 생성 방식으로 동작합니다. 이는 쿼리 수행 후 모든 결과 행을 생성하고 클라이언트로 한 번에 전달하는 방식으로 그 양이 많을수록 클라이언트 메모리 사용량은 증가할수밖에 없습니다.
하지만 Cursor 기반의 방식은 결과 집합에 대한 포인터 방식으로 결과 행을 점진적으로 가져올 수 있습니다. 따라서 클라이언트에서 쿼리를 수행 시 정해진 일정량(포인터)만큼 전송하는 방식으로, 트랜잭션 내에서 존재해야 하며, 명시적으로 트랜잭션을 닫아야 합니다. 이를 통해 클라이언트의 메모리 사용은 크게 감소할 수 있습니다.
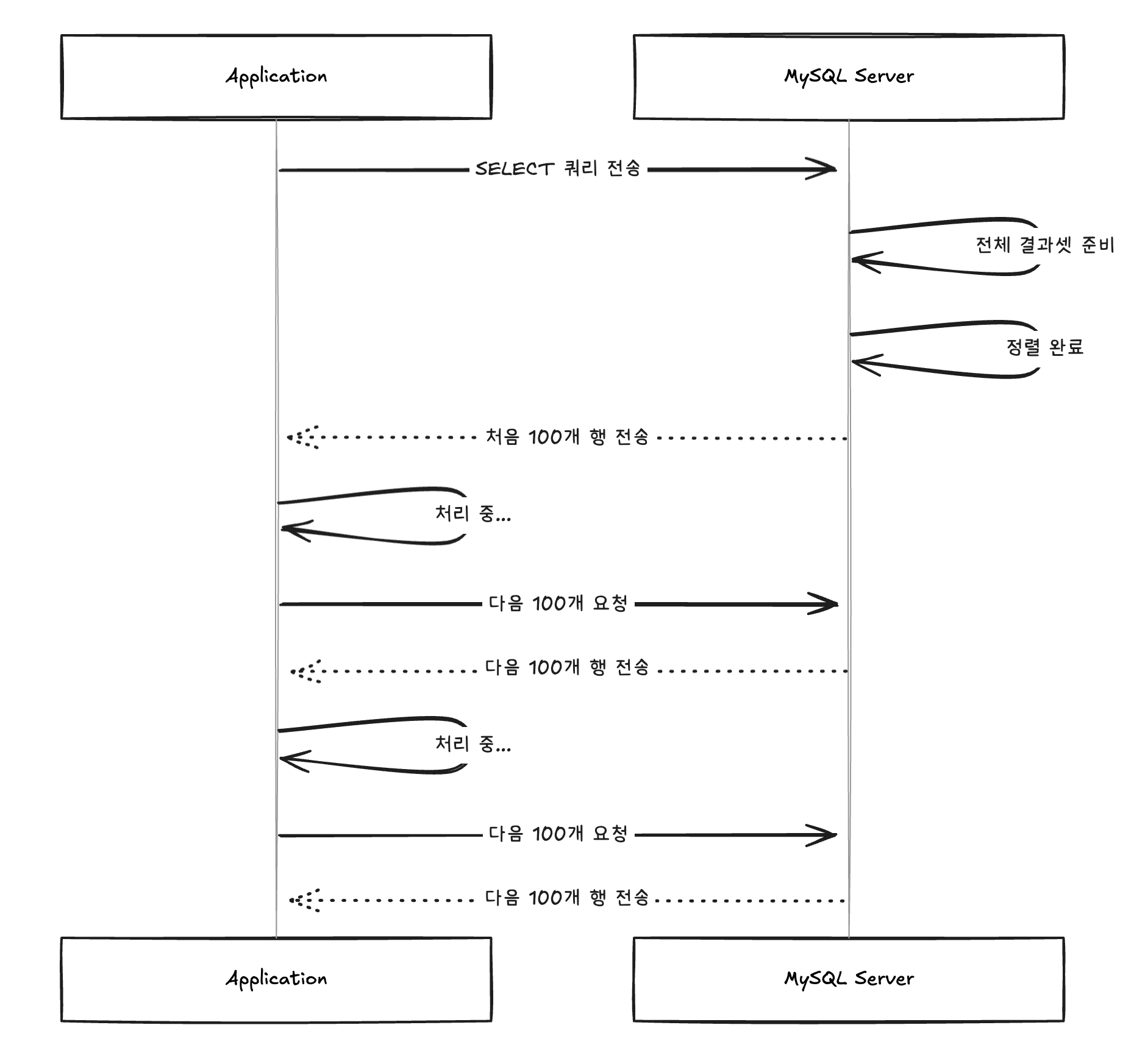
실제 쿼리문은 일반적인 SELECT문과 동일하게 한 번에 전달되는 것처럼 보이지만 실제 클라이언트 입장에서는 정해진 일정량만큼 데이터를 가져오는 방식입니다. 이러한 Cursor 방식은 몇 가지 설정이 있으면 가능합니다. 이는 MySQL과 Hibernate의 공식문서를 참고하여 구성이 가능합니다.
[MySQL 공식 문서]
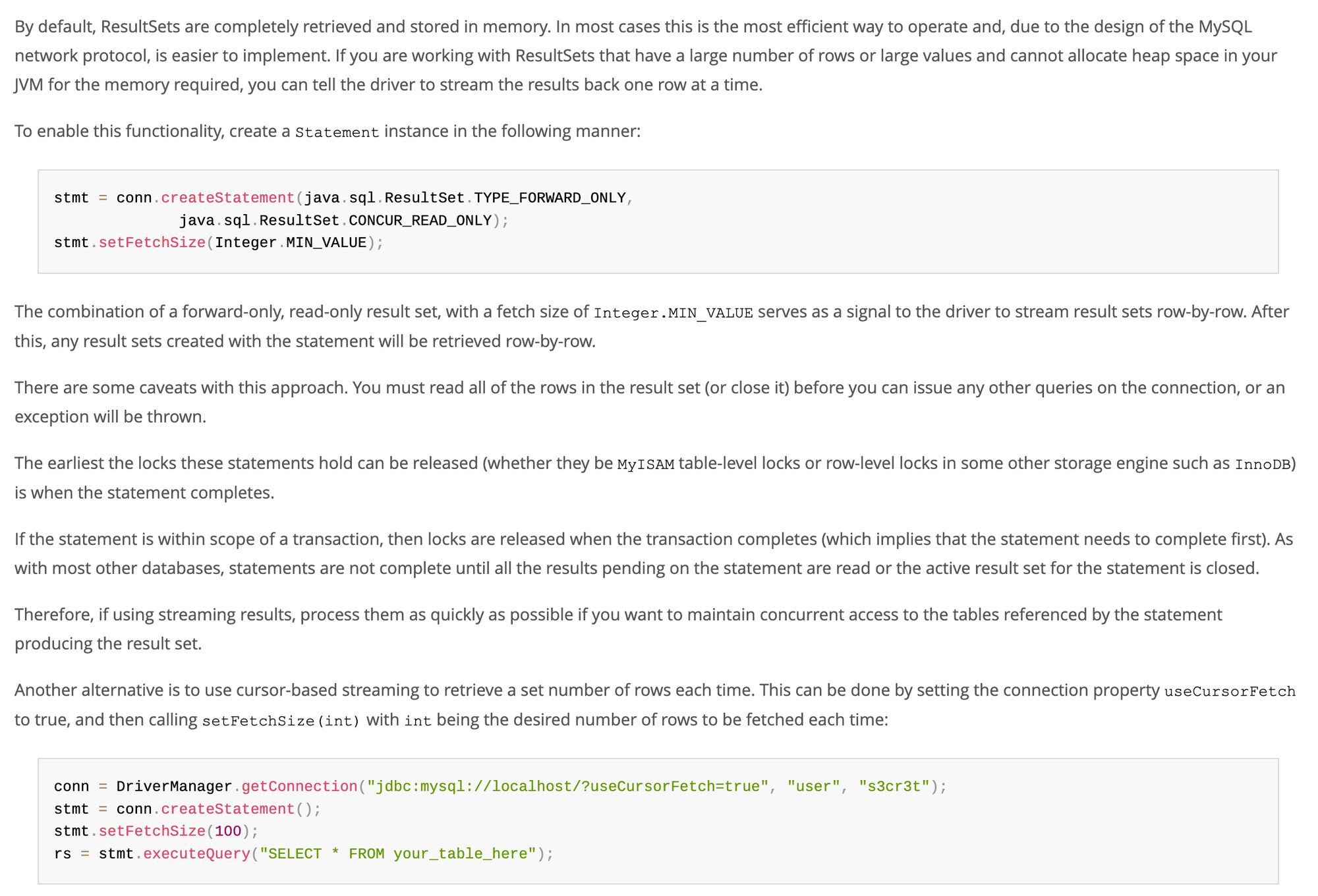
요약하자면, MySQL은 기본적으로 전체 결과를 메모리에 로드하기 때문에 OOM을 유발할 수 있고, 이를 해결하기 위해 TYPE_FOWORD_ONLY, CONCUR_READ_ONLY, setFetchSize(Integer.MIN_VALUE)를 활용해 Row-by-Row의 스트리밍 방식 또는 Cursor 스트리밍을 활용하여 useCursorFetch=true 옵션과 setFetchSize(100) 설정으로 배치 단위로 가져오는 방식이 있습니다. 이때, 네트워크 오버헤드 등을 고려하여 정산시스템에서는 Cursor 방식을 선택했습니다.
[Hibernate 공식문서]

해당 내용을 요약하자면, Query#scroll() 메서드를 통해 JDBC의 scrollable ResultSet을 활용한 서버 사이드 커서 기능을 제공하며, 이때, ScrollMode로 스크롤 방식을 지정할 수 있습니다. 이 결과로 반환되는 ScrollableResults는 내부적으로 ResultSet을 열어두고 데이터베이스와 연결을 계속 유지한 상태로 데이터를 조금씩 가져올 수 있습니다. 실제 동작 코드는 아래와 같습니다.
/**
* ResultsetRowsCursor.fetchMoreRows()
*/
private void fetchMoreRows() {
if (this.lastRowFetched) {
this.fetchedRows = new ArrayList(0);
} else {
synchronized(this.owner.getSyncMutex()) {
try {
// 중략..
// fetch size 결정
int numRowsToFetch = this.owner.getOwnerFetchSize();
if (numRowsToFetch == 0) {
numRowsToFetch = this.owner.getOwningStatementFetchSize();
}
if (numRowsToFetch == Integer.MIN_VALUE) {
numRowsToFetch = 1;
}
// 중략..
// MySQL에 command 전송
this.protocol.sendCommand(this.commandBuilder.buildComStmtFetch(this.protocol.getSharedSendPacket(), this.owner.getOwningStatementServerId(), (long)numRowsToFetch), true, 0);
Row row = null;
// 네트워크에서 row를 읽어 메모리에 저장(fetchSize 만큼)
while((row = (Row)this.protocol.read(ResultsetRow.class, this.rowFactory)) != null) {
this.fetchedRows.add(row);
}
// 중략..
}
}
}위 내용들을 조합하여 정산시스템에서는 Stream한 데이터처리가 가능하도록 DB조회 방식을 아래와 같은 방식으로 수정했습니다.
JPAQuery<SalesSettlementRaw> query = createSettlementRawFetchQuery(request)
.orderBy(
SALES_SETTLEMENT.transactionAt.desc(),
SALES_SETTLEMENT.paymentId.asc());
Session session = entityManager.unwrap(Session.class);
Query<SalesSettlementRaw> hibernateQuery = (Query<SalesSettlementRaw>) query.createQuery()
.unwrap(Query.class)
.setReadOnly(true)
.setFetchSize(100)
.setCacheable(false);
try (ScrollableResults<SalesSettlementRaw> results =
hibernateQuery.scroll(ScrollMode.FORWARD_ONLY)) {
int count = 0;
while (results.next()) {
SalesSettlementRaw entity = results.get();
processor.accept(entity);
if (++count % 100 == 0) {
session.clear();
}
}
}추가적으로 이때, JDBC URL 설정에 useCursorFetch=true 옵션 추가가 필요합니다. 최종적으로 위와 같은 코드를 통해 Cursor 방식을 통한 Stream을 활용한 조회 데이터 처리를 수행합니다. 또한 fetchSize 단위로 1차 캐시 영역을 삭제하여 메모리 리소스를 효율적으로 관리할 수 있습니다. Service 코드에서는 해당 Stream 데이터를 받아 임시 엑셀 파일에 작성을 수행하는 구조입니다.
물론 JDBC Template을 활용할 수도 있지만 해당 방식은 filter 기능이 있는 조회 기능에서 오히려 코드 복잡도를 높이고 많은 필드(24개)를 매핑하는 수작업 과정으로 인해 기존의 QueryDSL 방식을 활용했습니다.
나눠진 엑셀 파일 업로드
위와 같은 방법들로 메모리 부하의 작업은 어느 정도 해결이 되었다고 가정되는 상태지만, 출력된 엑셀 파일들에 대한 처리가 필요합니다. 데이터가 많지 않다면 불필요하게 여러 개의 엑셀 파일로 나눠서 생성할 필요가 없다는 점과 나눠졌다면 해당 엑셀 파일을 어떻게 사용자에게 전달할 것인가입니다.
우선, 최종 사용자인 재무팀이 사용하는 엑셀의 경우 한 시트에 보여줄 수 있는 행의 수는 Window Excel 기준 2007년 이후로 한 시트에 1,048,576행까지 표시가 가능합니다. 해당 행 수를 넘어갈 경우 시트를 나눠야 합니다. 이러한 제약에 따라 100만 건 이상의 데이터의 경우 어떻게 엑셀을 출력할 것인지에 대한 고민이 필요합니다.
문제가 된 대규모 정산시스템 데이터 출력의 경우 500만 건 이상이 되는 큰 데이터로 이 경우에는 한 시트 안에 모든 데이터를 넣기가 불가능합니다. 이에 100만 행 달성 이전에 시트를 나눠 생성하는 방법을 고민했지만 이는 엑셀 생성 시 CPU 성능을 고려하여 선택한 opencsv 라이브러리의 제약 사항(여러 시트 생성 불가능)으로 인해 불가능해 엑셀을 나눠서 생성할 수밖에 없습니다.
이에, 조회하는 데이터의 수가 100만 건 이하인 경우, 하나의 CSV에 출력하며, 그 이상인 경우 엑셀 파일을 나눠서 zip 파일의 형태로 전달하는 방식을 선택했습니다. 예를 들면 아래와 같습니다.
@Async
public void createSalesSettlementRawCsvData(SalesSettlementReconciliationRequest request) {
if (dataSize <= 1_000_000) {
log.info("Data size <= MAX_CSV_RECORDS records: {}", dataSize);
Path csvFilePath = excelMonthlyTaskManager.writeSalesSettlementCsv(request, tempDirectory, fileName);
} else {
DateUtils.partitionByDayUnit(request.requestStartDate(), request.requestEndDate(), 3)
.forEach(partitionDate -> {
//..중략
CompletableFuture<Void> completableFuture = excelMonthlyTaskManager.execute(() -> {
SalesSettlementReconciliationRequest excelRequest = request.createExcelRequest(startDate, endDate);
excelMonthlyTaskManager.writeSalesSettlementCsv(excelRequest, tempDirectory, csvFileName);
});
//..중략
Path zipPath = FileUtils.compressFiles(tempDirectory, fileName, ".csv");
}이제 남은 부분은 엑셀을 어떻게 사용자에게 전달할 것인가입니다. 현재 프로세스는 비동기적인 방식으로 사용자는 이미 요청 완료 응답을 받은 상태입니다. 서버는 생성된 엑셀 혹은 zip 파일을 어딘가에 가지고 있어야 하며, 이를 사용자가 다운로드할 수 있도록 기능을 제공해야 합니다. 정산시스템에서는 S3의 PreSigned URL과 MultipartUpload를 활용하여 이를 해결했습니다.
[PreSigned URL]
PreSigned URL은 서버에서 AWS 자격증명으로 암호화 서명된 임시 URL을 생성하며, 클라이언트 입장에서는 AWS 자격 증명 없이도 제한된 시간에 S3에 직접 업로드 혹은 다운로드를 할 수 있는 방식입니다. 이때 GetObjectRequest를 활용해 다운로드만 가능하도록 생성이 가능하며, 클라이언트는 이를 통해 다운로드를 수행합니다. 다만 이는 제한된 시간이 넘어가면 다운로드가 불가능하기 때문에, 만료 시간이 지난 이후에는 재발급 로직이 필요합니다.(공식문서)
public PreSignResult getPreSignedUrl(String key) {
GetObjectRequest getObjectRequest = GetObjectRequest.builder()
.bucket(awsS3Properties.bucket())
.key(key)
.build();
PresignedGetObjectRequest presignedGetObjectRequest = s3Presigner.presignGetObject(preSignedUrlBuilder -> preSignedUrlBuilder
.signatureDuration(Duration.ofMinutes(DEFAULT_SIGNED_URL_DURATION_MINUTES))
.getObjectRequest(getObjectRequest));[MultipartUpload]
해당 방식은 대용량 파일을 여러 조각(최소 5MB)으로 나눠서 병렬로 업로드할 수 있으며, 이를 S3가 최종적으로 조립하여 하나의 파일로 완성하는 방식입니다. 이러한 방식은 네트워크 장애 등 여러 이유로 실패한 조각만 재전송하여 파일을 다시 완성할 수 있습니다.
엑셀 출력 데이터가 많은 경우 실제 파일의 크기는 최소 50MB 이상이며, 5월 한 달의 경우 zip 파일로만 약 140MB입니다. 이러한 경우 MultipartUpload 방식은 하나의 파일을 여러 조각으로 나누어 병렬적으로 S3에 업로드할 수 있기 때문에 정산시스템에는 효율적인 방식입니다. 더 많은 기능 및 부가적인 설명은 공식문서를 참고 바랍니다.
ExecutorService threadPool = Executors.newFixedThreadPool(totalParts);
List<CompletableFuture<CompletedPart>> uploadFutures = new ArrayList<>();
for (int partIndex = 0; partIndex < totalParts; partIndex++) {
final int partNumber = partIndex + 1;
final int position = uploadMultiPartBuffer * partIndex;
final int partSize = (int) Math.min(uploadMultiPartBuffer, fileLength - position);
uploadFutures.add(CompletableFuture.supplyAsync(() -> {
try {
try (RandomAccessFile accessFile = new RandomAccessFile(file, "r")) {
byte[] buffer = new byte[partSize];
accessFile.seek(position);
accessFile.readFully(buffer);
UploadPartRequest uploadPartRequest = UploadPartRequest.builder()
.bucket(awsS3Properties.bucket())
.key(key)
.uploadId(uploadId)
.partNumber(partNumber)
.contentLength((long) partSize)
.build();
UploadPartResponse uploadPartResponse = s3Client.uploadPart(uploadPartRequest,
RequestBody.fromBytes(buffer));
return CompletedPart.builder()
.partNumber(partNumber)
.eTag(uploadPartResponse.eTag())
.build();
}
} catch (Exception e) {
log.error("Failed to upload part {}: {}", partNumber, e.getMessage());
throw new RuntimeException("Failed to upload part " + partNumber, e);
}
}, threadPool));
}파일대기열
서버에서의 데이터 조회, 엑셀 생성, 업로드까지 완료했다면 클라이언트 입장에서는 다운로드가 가능해야 합니다. 기존 동기 방식에서 비동기적으로 진행되는 프로세스의 변경에 따라 사용자에게 보여줄 그리고 현재 파일의 진행 상황과 완료 이후 엑셀 파일을 다운로드받을 수 있는 파일 대기열이 필요합니다.
@Entity
@Table(name = "file_queue")
public class FileQueue extends BaseEntity {
@Enumerated(value = EnumType.STRING)
private FileType fileType;
private String fileName;
@Enumerated(value = EnumType.STRING)
private ProgressType progressType;
private String uploadKey;
private String downloadUrl;
private LocalDateTime expirationDate;
}각 필드 중 중요한 부분은 uploadKey와 downloadUrl 그리고 expirationDate입니다. 최종적으로 사용자는 서버에서 만든 PreSigned URL을 downloadUrl 컬럼을 통해 제공받으며 이를 통해 다운로드를 수행합니다. 서버는 URL을 생성하면서 만료 시간을 계산하여 expirationDate에 기록하고 사용자는 해당 시간을 초과한 경우 S3 uploadKey를 통해 PreSigned URL을 재발급받을 수 있습니다. (이때 만료는 동일하게 1분입니다.)
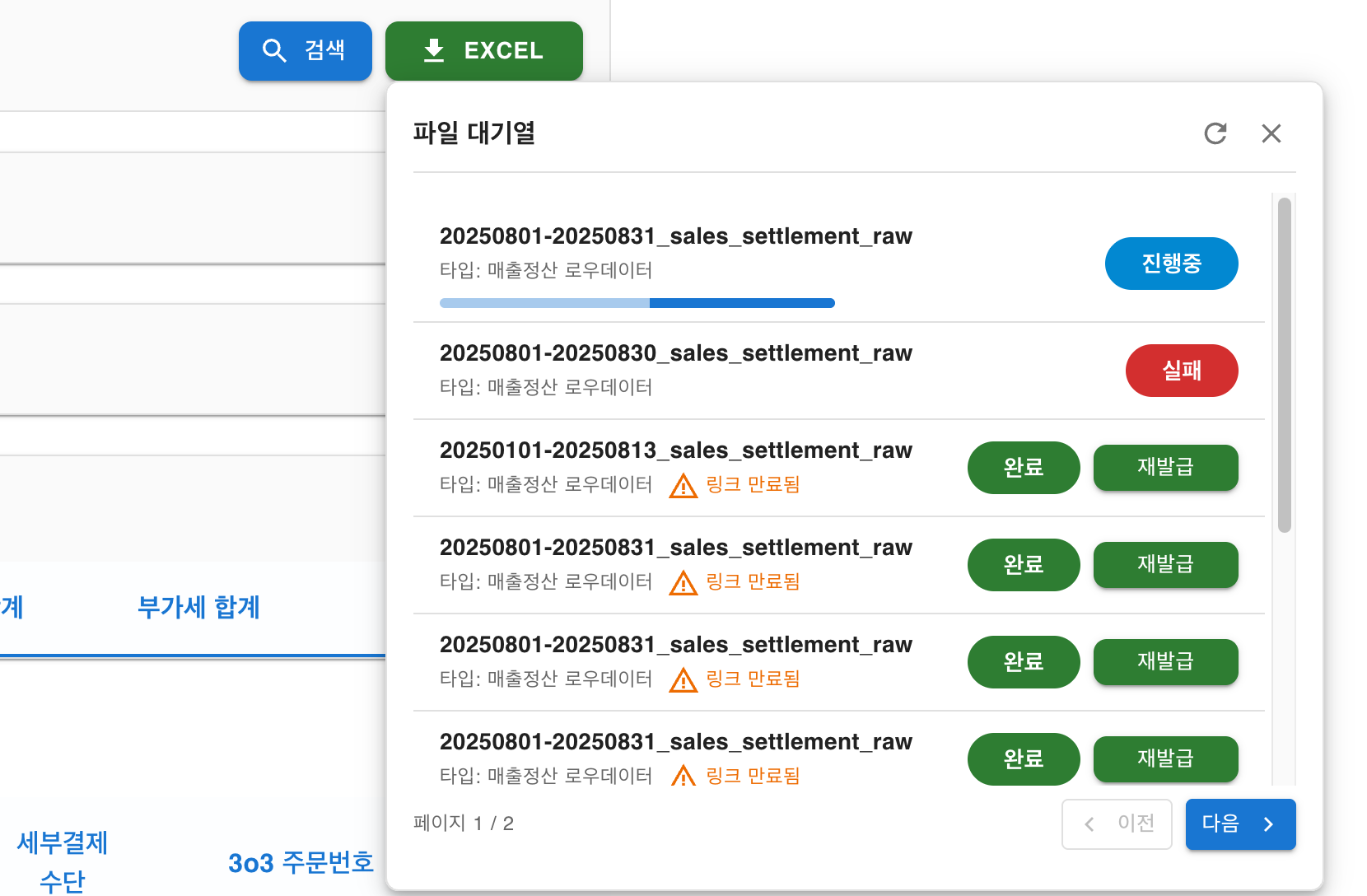
이러한 파일 대기열은 매번 요청시마다 엑셀파일을 생성했던 기존방식과 다르게 언제든 해당 날짜의 파일을 서버 리소스 소비 없이 링크 재발급 버튼을 통해 Storage에서 다시 받을 수 있는 장점이 있습니다.
마치며
정리하자면, 서버는 사용자의 엑셀 데이터 요청을 받은 후 먼저 해당 범위의 데이터가 몇 건인지 파악합니다. 이때 100만 건 이하의 데이터는 단일 CSV로, 초과하는 경우에는 3일씩 조회 일자를 나누어 Stream을 활용한 데이터 처리와 DB Cursor 조회를 통해 여러 개의 CSV 파일을 하나의 ZIP 파일로 압축합니다.
이후 생성된 파일을 외부 Storage인 S3 Bucket에 MultipartUpload방식을 통해 병렬 처리로 업로드하며, 이때 클라이언트가 다운로드할 수 있도록 PreSigned URL을 제공합니다. 클라이언트는 파일 대기열을 통해 해당 파일들의 링크 만료 여부 확인과 재발급이 가능하며, public한 링크로 파일 다운로드가 가능한 구조입니다.
이러한 방식의 처리로 정산시스템은 기존의 요청으로는 처리할 수 없었던 대량의 데이터를 OOM 없이 해결할 수 있게 되었습니다. 또한 응답이 오래 걸려 발생하던 BackOffice Gateway의 재시도 정책으로 인한 부가적인 문제도 해결할 수 있었습니다. 실제 Grafana 지표를 보면 이전보다 안정적인 시스템 리소스를 확인할 수 있습니다.
서버 측의 이점 외에 사용자인 재무팀의 입장에서도 해당 작업을 동기적으로 기다리다 결국 다운로드가 불가능했던 불편함과 날짜를 쪼개가며 몇 번씩 다운로드해야 했던 불편한 작업에서 벗어나 다른 작업을 수행하며 파일 대기열을 통해 언제든 다운로드할 수 있어 업무 리소스 확보가 가능했습니다.
대부분의 정산시스템은 엑셀 다운로드 날짜에 제한을 두고 운영하는 경우가 많습니다. 이번 개선 작업을 진행하면서 '꼭 날짜 제한을 두어야만 할까?'라는 의문이 들었습니다. 제한이라는 제약이 사용자보다는 개발자가 편하기 위한 방법 중 하나는 아닐까 하는 생각도 했습니다.
물론 주어진 시스템 상황과 환경에 따라 선택된 방법이겠지만, 현재 우리 시스템에서 주어진 리소스와 환경 안에서 최대한의 성능을 뽑아보자는 생각으로 개선 작업을 수행했습니다. 정산 시스템이라는 특성을 이해하고 나니 좀 더 넓은 시각으로 문제를 바라볼 수 있었고, 이를 통해 좀 더 다양한 해결 방법들을 고민해볼 수 있었습니다.
이번 개선은 병렬 프로그래밍, Stream 기반 데이터 처리, 그리고 DB Cursor 조회라는 세 가지 기술이 결합되면서 만들어낸 결과였습니다. 날짜 단위로 나눈 병렬 처리는 작업 시간을 단축시켰고, Stream과 Cursor 방식은 메모리에 모든 데이터를 올리지 않고도 대용량 데이터를 처리할 수 있게 해주었습니다.
이를 통해 올바른 기술을 조합하면 제한된 리소스 안에서도 충분히 해결 가능하다는 것을 확인할 수 있었습니다. 특히 사용자 경험을 희생하지 않으면서도 시스템의 안정성을 확보할 수 있다는 점에서, 제약이 아닌 최적화를 통한 문제 해결의 가치가 상당히 크다는 것을 경험할 수 있었습니다.
글 | 엄태권디자인 | 조재원
본 콘텐츠의 저작권은 (주)자비스앤빌런즈에게 있으며, 본 콘텐츠에 대한 무단 전재 및 재배포를 금지합니다