

23년 7월부터 자비스앤빌런즈 인프라팀은 Terraform을 이용한 IaC(Infrastructure as Code) 전환을 시작했습니다. Terraform은 Hashicorp Configuration Language(HCL)로 인프라를 효율적으로 빌드, 변경 및 버전 관리할 수 있는 인프라 코드 도구입니다. 코드로 인프라를 구축하기 때문에 환경 변경 및 배포 등 반복 작업에 드는 시간을 줄일 수 있을 뿐 아니라 변경 사항을 추적하고 감사할 수 있는 장점이 있습니다. 현재는 대부분의 리소스를 코드로 관리하고 있으며, AWS CodePipeline과 함께 배포 자동화를 구현하여 업무 생산성과 효율성을 높였습니다.
자비스앤빌런즈가 인프라 리소스를 배포하는 방법
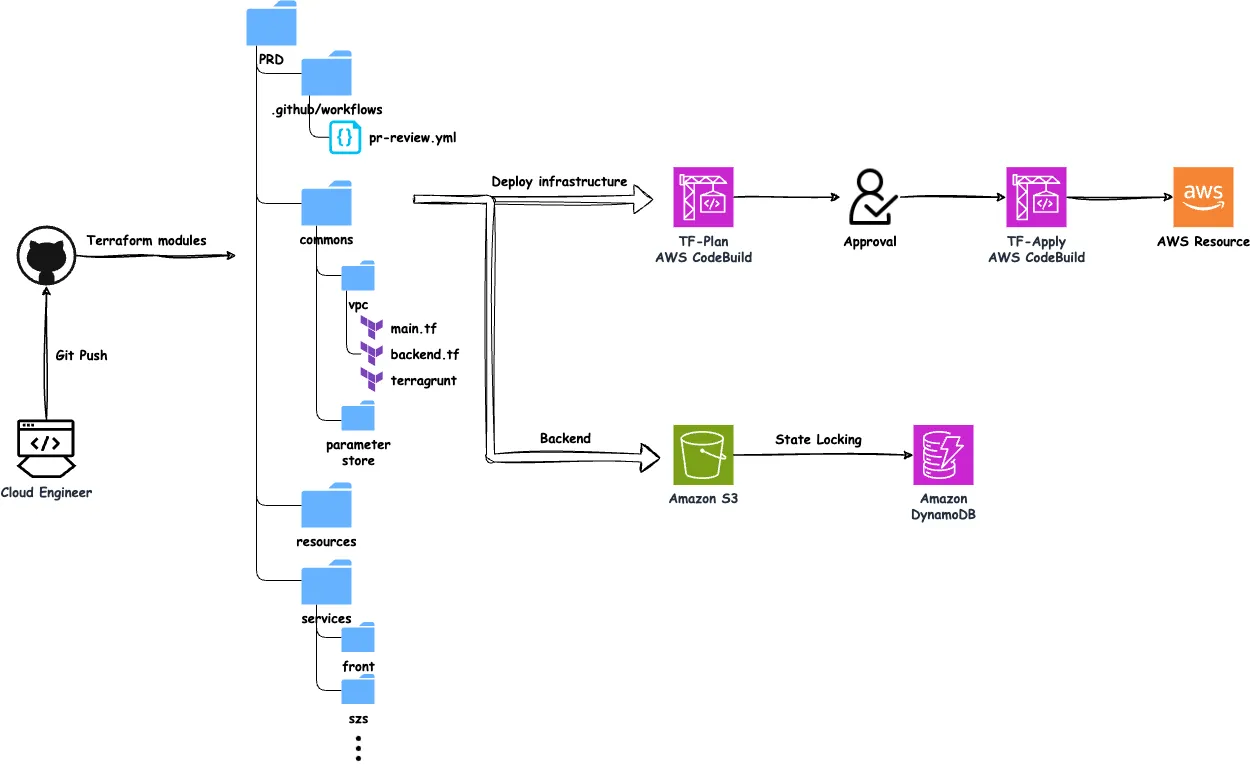
주요 구성 요소
- 코드 구조
- 인프라 코드는 GHE repository로 관리됩니다.
- 구성 파일은 환경별로 commons, resources, services 등에 저장되며 각각의 디렉토리는 인프라의 개별 컴포넌트(VPC, S3, Cloutwatch 등)를 위한 구성 파일(
main.tf,backend.tf,terragrunt.hcl)과 모듈을 포함하고 있습니다. - 개별 리소스를 표준화된 설정으로 캡슐화한 별도의 Terraform 모듈을 사용합니다. 환경 간 일관성을 유지하며 리소스를 쉽게 재사용 할 수 있습니다.
- Backend
- Amazon S3: Terraform state 파일을 원격 저장소인 Amazon S3에 저장하여 state 파일의 유실을 방지합니다. 설정에 따라서 S3, Consul, ETCD 등 다양한 Backend type을 사용할 수 있습니다.
- DynamoDB: 동시에 같은 파일을 수정하지 못하도록 하기 위해 DynamoDB 테이블에 작업에 대한 Lock을 생성합니다.
Happily Ever After…?
Terraform import와 IaC 전환은 인프라팀의 업무 자동화의 기틀을 마련한 계기가 됐고, 서비스가 증가함에 따라 인프라의 코드화는 생산성 측면에서 빛을 발하기 시작했습니다. 하지만 Terraform 전환 후 약 9개월 만에 예기치 못한 에러를 마주했습니다.
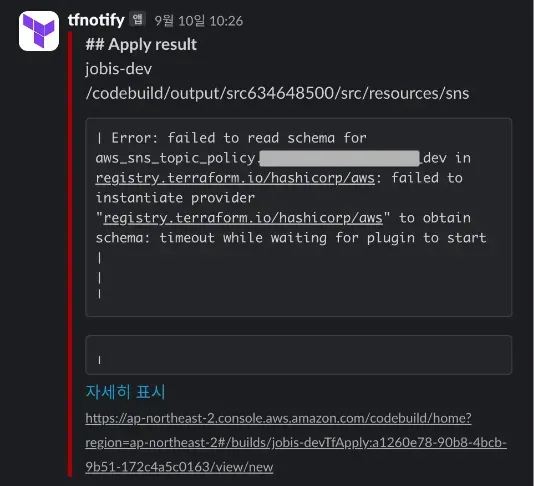
개발 환경에서 처음 오류가 발생하기 시작했고, 시간이 지남에 따라 결국 스테이징 환경까지 동일한 오류가 확산됐습니다. 버전이나 네트워크 문제인 줄 알았으나 모듈 수가 증가함에 따라 처리 속도 저하 및 에러 발생 빈도도 함께 증가하는 문제임을 확인했습니다.
GitHub Actions vs. AWS CodePipeline 비교
기존 CI/CD는 AWS CodePipeline을 사용하고 있었으나, CodePipeline은 단계 간 순차 실행으로 병렬 처리에 한계가 있어 모듈 처리 시 성능 저하가 발생했습니다. 또한 AWS CodePipeline에서는 병렬로 실행된 작업의 결과를 자동으로 종합하여 다음 단계로 전달하는 기능이 기본적으로 제공되지 않아 워크플로우의 확장성 및 관리 효율성에서 Github Actions에 비해 불리한 점이 있었습니다.
- 비용 비교
Github Actions의 경우self-hosted runners및 다양한 인스턴스 크기 선택으로 비용 효율성을 극대화할 수 있습니다. 예를 들어, 동일한 워크로드 처리 시, AWS CodeBuild에 비해 Github Actions는 사용량 기반의 최적화된 가격 정책을 제공하여 단위 작업당 비용이 더 낮습니다.
| Service | Cost per minute | Specs |
|---|---|---|
| Gradlebuild general1.medium | $0.01 | 4CPU, 7GB |
| Spot Instance m5a.large | $0.0006 | 2CPU, 8GB |
| Spot Instance m5a.xlarge | $0.0013 | 4CPU, 16GB |
2. 성능 비교
빌드 및 파이프라인 실행 시간도 Github Actions가 더 빠르게 나타났습니다. 특히, Gradle 캐시를 활용한 Github Actions는 AWS CodePipeline과 비교해 전반적인 파이프라인 속도가 크게 개선되었습니다.
| CodeBuild + CodePipeline (8CPU, 15GB) | Github Actions (2CPU, 8GB) | Github Actions (with Gradle Cache, 2CPU, 8GB) |
|---|---|---|
| Gradle Build Time | 83s | 53s |
| Stage Time | 93s | 77s |
| Total Pipeline Time | 128s | 83s |
이러한 테스트 결과, Github Actions로 CI/CD 파이프라인을 전환하기로 최종 결정했습니다.
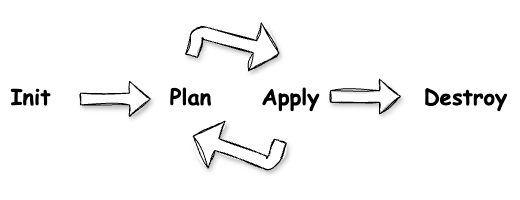
예상치 못한 모듈 용량
Github Actions로 전환하면서 Terraform 코드 반영 작업은 비교적 빠르게 완료될 것이라 예상했습니다. 그러나 예상과 달리, 초기화 과정에서 디스크 용량 부족 문제가 발생하며 작업이 지연되었습니다. 특히, Terraform의 초기화(init) 과정에서 대량의 모듈과 프로바이더를 다운로드하고 캐싱하면서 디스크 공간이 급격히 소모되었습니다. 이로 인해 간헐적으로 "no space left on device" 오류가 발생하며 CI/CD 파이프라인이 중단되는 상황을 맞닥뜨리게 되었습니다.
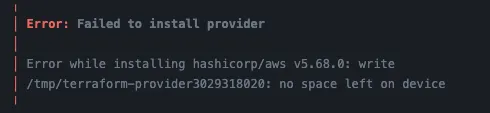
Terraform은 init → plan → apply의 단계를 거쳐 리소스를 생성하는데 작동 원리는 다음과 같습니다.
생성하려는 리소스를 코드로 정의하고, 초기화 과정을 거쳐 작성자의 의도와 일치하는지 plan을 확인합니다. 문제가 없을 경우 정의한 그대로 반영 및 리소스를 생성하게 됩니다. 디스크 에러는 이 plan 단계에서 진행하는 init 과정에서 발생하고 있었습니다.
Terraform init?
terraform init은 코드에서 정의된 모든 리소스와 모듈을 사용하기 위해 필요한 초기 설정을 수행합니다. 이 단계에서는 주로 다음과 같은 작업이 이루어집니다:
- 플러그인 및 프로바이더 설치:
terraform init은 코드에 명시된 각 프로바이더(예: AWS, Azure 등)를 설치하고, 필요한 플러그인과 버전을 가져옵니다. 이때 플러그인은.terraform디렉토리에 다운로드하며 프로바이더가 많아질수록, 그리고 특정 플러그인의 크기가 클수록 디스크 공간을 많이 차지하게 됩니다. - 모듈 다운로드 및 설정: 코드에서 외부 모듈을 사용하는 경우,
init은 이를 참조하고 다운받아.terraform/modules디렉토리에 저장합니다. 이를 통해 모듈이 여러 Terraform 구성을 통해 반복적으로 사용될 수 있지만, 모듈의 개수와 크기에 따라 디스크 공간이 추가적으로 요구됩니다. - 백엔드 설정: Terraform은 상태 파일을 저장하는 백엔드(S3, GCS 등)를 설정합니다. 이 과정에서 백엔드 구성 검증이 이루어지며, 이 역시 프로세스의 일부로 디스크 리소스를 사용하게 됩니다.
인프라팀에서 관리하는 프로젝트는 환경 당 약 80여개 이상으로 구성되어 있으며, 각 서비스는 개별적인 Terraform 구성을 가지고 있어 .terraform 디렉토리의 용량이 빠르게 증가하게 된 상황이었습니다.
기존에는 러너가 수행하는 작업이 많지 않아 EBS 볼륨이 크지 않았고 단순하게 용량을 증설하고 진행하면 문제가 해결될거라 생각했습니다.
한 고비 넘으면 또 한 고비
처음에는 러너가 수행하는 작업량이 많지 않아 EBS 볼륨 크기에 큰 신경을 쓰지 않았습니다. 단순히 디스크 용량을 증설하면 문제는 해결될 것이라 생각했으나 볼륨을 증설한 후 "starves it for CPU/Memory"라는 에러가 발생하며 러너가 다운되기 시작했습니다.

모니터링을 통해 자세히 확인해보니, CPU는 거의 사용되지 않았지만 메모리가 부족한 상황이었습니다. 이에 따라 기존의 인스턴스 타입(2 core, 8GB 메모리)에서 8 core, 16GB 메모리로 인스턴스를 업그레이드 했으나, 여전히 러너가 비정기적으로 다운되는 현상은 해결되지 않았습니다. 이 문제는 리소스 부족 외에도 Terraform의 실행 단계에서 발생하는 비효율적인 작업들이 영향을 미친다는 것을 의미했습니다.
해결 방안
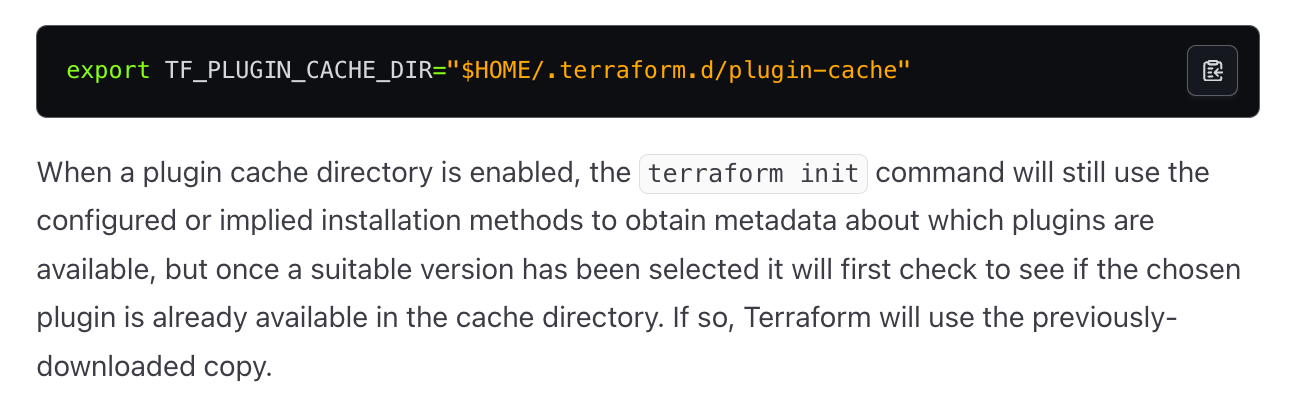
1. Provider Cache Plugin 적용
Terraform init 과정에서 매번 프로바이더를 다운로드하는 비효율성을 해결하기 위해 Provider Cache Plugin을 도입했습니다. 이를 통해 동일한 프로바이더를 반복적으로 다운로드하지 않고, 러너의 로컬 디스크에 캐싱된 프로바이더를 재사용하도록 구성했습니다. 이 방식은 디스크 용량과 네트워크 사용량을 크게 줄였을 뿐만 아니라 초기화 시간도 단축시켰습니다.
2. Terragrunt 활용
Terragrunt는 Terraform의 확장 도구로, 복잡한 Terraform 프로젝트를 더 쉽게 관리하고 실행할 수 있도록 돕습니다.
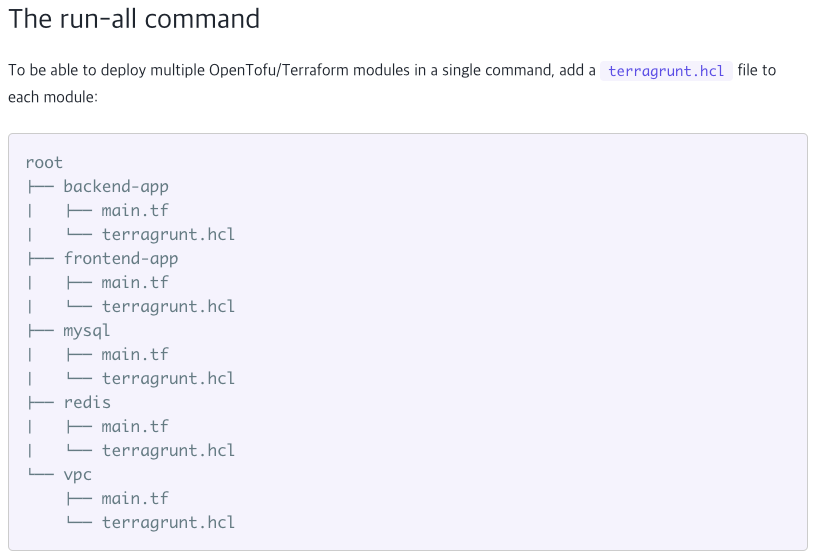
- 모듈 래핑 및 자동화
Terragrunt는 Terraform 모듈을 래핑하여 구성 파일을 더욱 간단하게 관리할 수 있도록 돕습니다. 이를 통해 각 환경(dev, stg, prd)에 따라 중복되는 설정을 줄이고, 유지 보수성을 향상시킵니다. - 자동 Backend 설정
각 Terraform 모듈에 대해 별도로 Backend 설정을 작성할 필요 없이, Terragrunt를 사용하면 모든 모듈에서 자동으로 동일한 S3와 DynamoDB를 활용한 상태 파일 관리 및 잠금(Locking)을 설정할 수 있습니다. - 병렬 실행 및 실행 제한
Terragrunt는 병렬 실행을 기본 지원하며,--parallelism옵션을 통해 병렬 작업 수를 세밀하게 조정할 수 있습니다. 기존의 Terraformparallelism옵션은 적용할 리소스 단위로 병렬성을 제어하지만, Terragrunt는 모듈 단위의 병렬 실행을 제어하여 보다 큰 수준에서 부하를 분산할 수 있습니다. 이를 통해 리소스 생성 시 시스템에 가해지는 부하를 효과적으로 제어했습니다.
전환 완료 및 성과
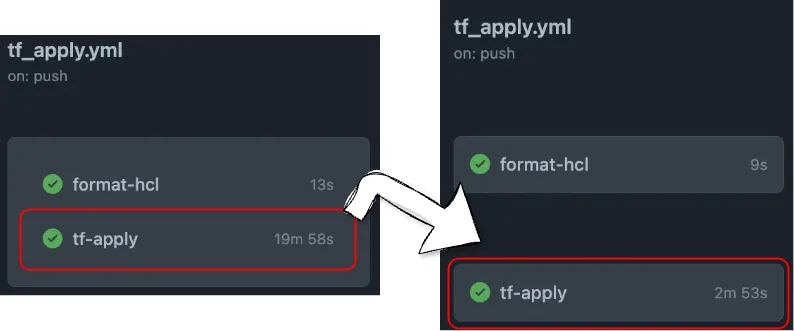
이러한 최적화 과정을 통해 Github Actions로의 CI/CD 파이프라인 전환을 성공적으로 완료했습니다. Provider Cache Plugin과 Terragrunt 활용은 예상 이상의 성능 향상을 가져왔습니다.
기존 AWS CodePipeline 환경에서 평균 20분 가까이 소요되던 배포 프로세스는 Github Actions 전환 후 3분 내외로 단축되었습니다. 즉, 약 85% 이상의 시간 절감과 더불어 인프라팀의 생산성을 크게 향상시켰습니다.
이로 인해 반복적인 배포 작업의 피로도가 감소했을 뿐만 아니라, 긴급한 수정 사항을 보다 신속하게 배포할 수 있는 민첩성을 확보하게 되었습니다.
Github Actions 전환 후 인프라 배포 아키텍처
전환 후 아키텍처는 Github Actions를 중심으로 구성되어, 기존 AWS CodePipeline 대비 더욱 유연하고 효율적인 CI/CD 프로세스를 제공합니다.
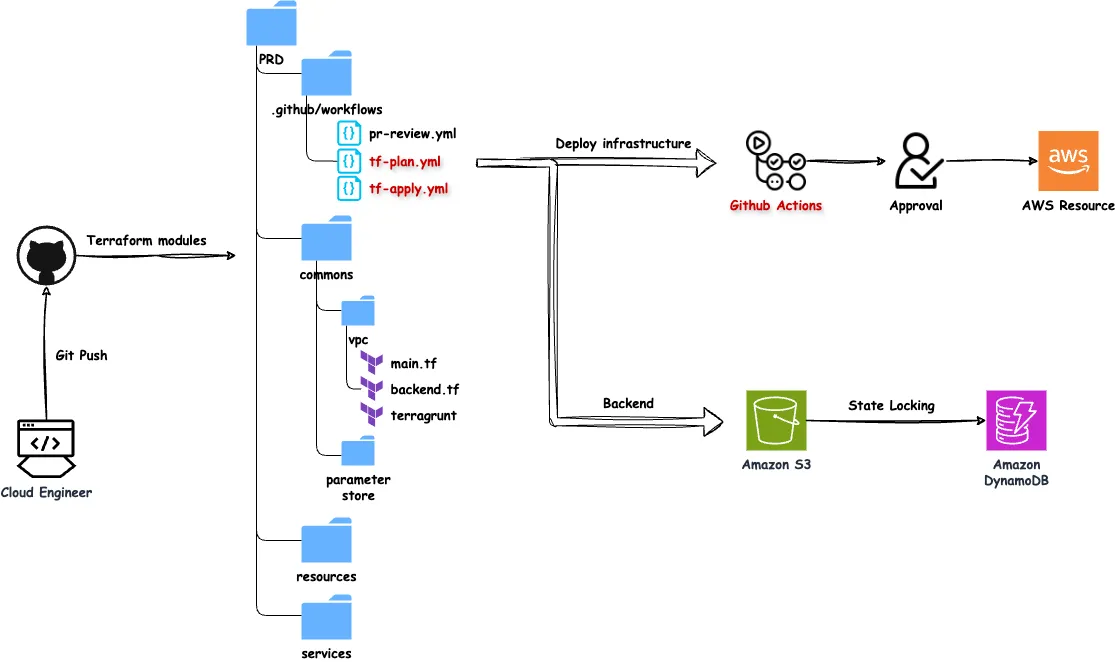
- Git Push
코드를 변경하고 Github에 push하면,.github/workflows디렉토리에 정의된 워크플로우가 실행됩니다. 워크플로우는tf-plan.yml과tf-apply.yml로 구성되어 있습니다. - Terraform Plan 및 Apply
tf-plan.yml: Terraform의 변경 사항을 미리 검토합니다.tf-apply.yml: 검토된 변경 사항을 인프라에 적용합니다. 적용 전에는 반드시 승인 절차를 거쳐야 하며, 이를 통해 변경의 안전성을 보장합니다.
- State Management
Terraform의 상태 파일은 S3에 저장되며, DynamoDB를 활용하여 State Locking 기능을 구현함으로써 다중 작업 환경에서도 충돌을 방지합니다. - Approval Workflow
인프라 변경은 자동화된 워크플로우와 함께 승인 절차를 포함하여, 변경이 프로덕션 환경에 적용되기 전에 인프라 관리자의 확인을 거칩니다. 이를 통해 높은 수준의 신뢰성과 안정성을 확보합니다.
마치며
이번 전환은 단순한 CI/CD 툴의 변경을 넘어, 인프라 관리의 효율성을 한층 더 높이고 팀의 운영 부담을 줄이는 중요한 전환점이 되었습니다. 특히, 개발과 배포 속도를 대폭 향상시키는 동시에 안정성과 관리 효율성을 모두 달성할 수 있었습니다. 앞으로도 다양한 활동을 이어나갈 예정이니 많은 관심 부탁드립니다. 감사합니다.
글 |
박은영
디자인 |
박서영
본 콘텐츠의 저작권은 (주)자비스앤빌런즈에게 있으며, 본 컨텐츠에 대한 무단 전재 및 재배포를 금지합니다