

삼쩜삼은 세금 신고 도움 플랫폼으로서, 특히 고객들의 종합소득세 신고가 집중되는 5월에는 트래픽이 폭발적으로 증가합니다. 이러한 상황에서 프론트엔드와 백엔드 개발자들이 성능 최적화를 위해 총력을 다하는 만큼, 데이터베이스 관리에서도 핵심적인 역할을 담당하고 있습니다.
이번 포스팅에서는 트래픽이 급증하는 5월을 대비하여 데이터베이스를 어떻게 관리했는지에 대해 다루려고 합니다. 구체적으로 다음과 같은 세 가지 주요 분야에 초점을 맞추었습니다.
- 모니터링 시스템 구축: OpenSearch JDBC Plugin을 활용한 모니터링 시스템
- Multi Source Replication을 활용한 RDS 자원 최적화: 운영 환경 부하 분산을 위한 복제 인스턴스 구축
- 커밋 지연 해소를 위한 파라미터 최적화: DML 성능 개선을 위한 파라미터 최적화
1. 모니터링 시스템 구축
초기 삼쩜삼 서비스는 모놀리식 형태의 데이터베이스를 운영하여, AWS CloudWatch 메트릭만으로도 충분한 모니터링 기능을 제공받을 수 있었습니다. 그러나 서비스가 점차 확장됨에 따라 각 서비스 간의 결합도가 높아지고, 데이터베이스 리소스 사용에 한계가 발생하기 시작했습니다. 삼쩜삼은 서비스의 유연성과 확장성을 고려하여 MSA 구조로의 전환을 결정했지만, 그로 인해 관리해야 할 포인트도 크게 늘어났습니다.
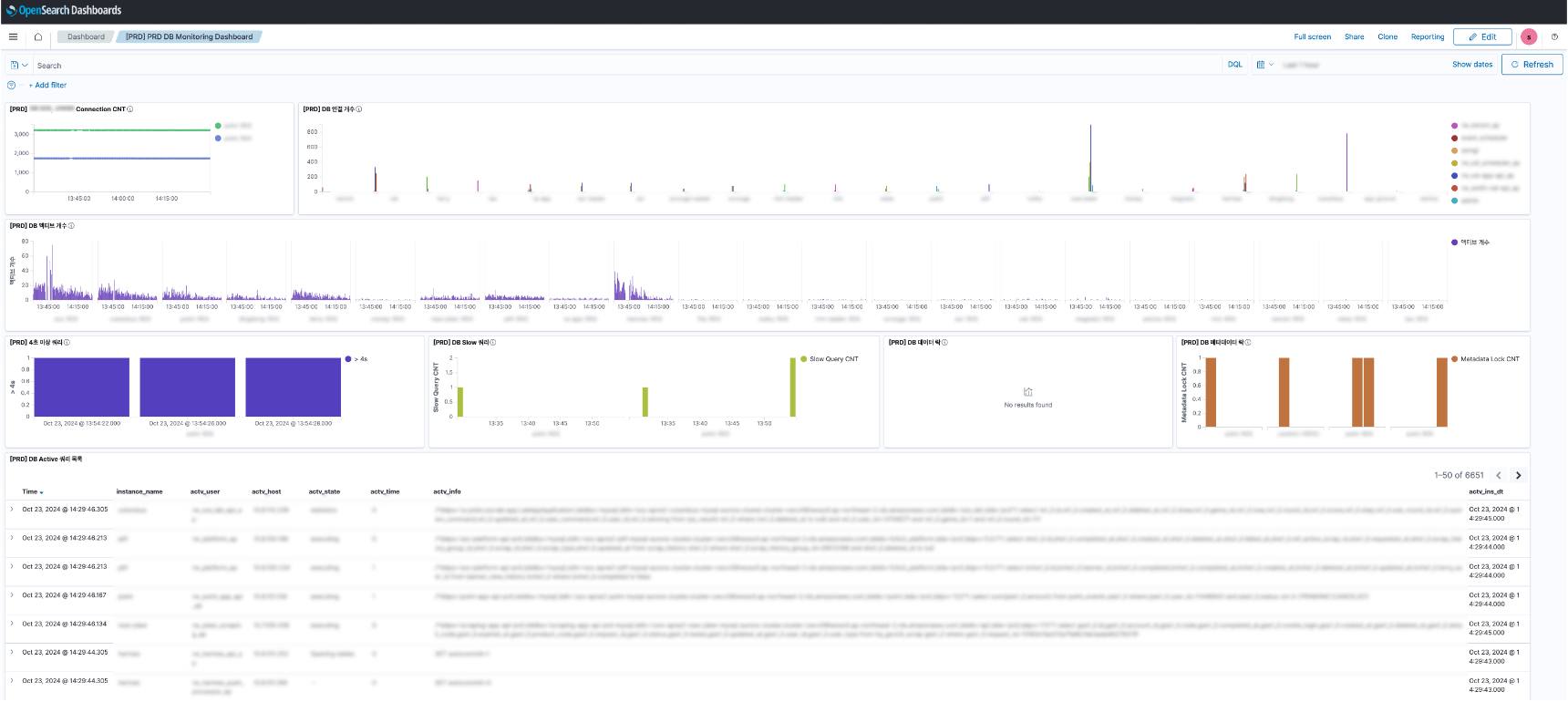
이러한 변화로 인해 통합된 모니터링 대시보드의 필요성이 대두되었고, OpenSearch와 Logstash를 결합한 모니터링 시스템을 구축하기로 결정하였습니다.
- 오픈서치(OpenSearch)란?
오픈서치는 AWS에서 제공하는 대용량의 데이터를 빠르게 검색하고 분석할 수 있는 오픈소스 분산 검색 엔진입니다. 원래 엘라스틱서치(Elasticsearch)에서 파생된 프로젝트로, 텍스트 검색, 로그 분석, 모니터링 등 다양한 용도로 사용됩니다. 오픈서치를 사용하면 대량의 데이터를 실시간으로 인덱싱하고, 복잡한 검색 및 집계 작업을 효율적으로 수행할 수 있습니다.
- 로그스태시(Logstash)란?
로그스태시는 데이터 파이프라인 도구로, 다양한 소스로부터 데이터를 수집하고 변환하여 원하는 대상으로 보낼 수 있습니다. 로그스태시는 입력(input), 필터(filter), 출력(output)의 세 단계로 구성되어 있어 유연한 데이터 처리 작업이 가능합니다.
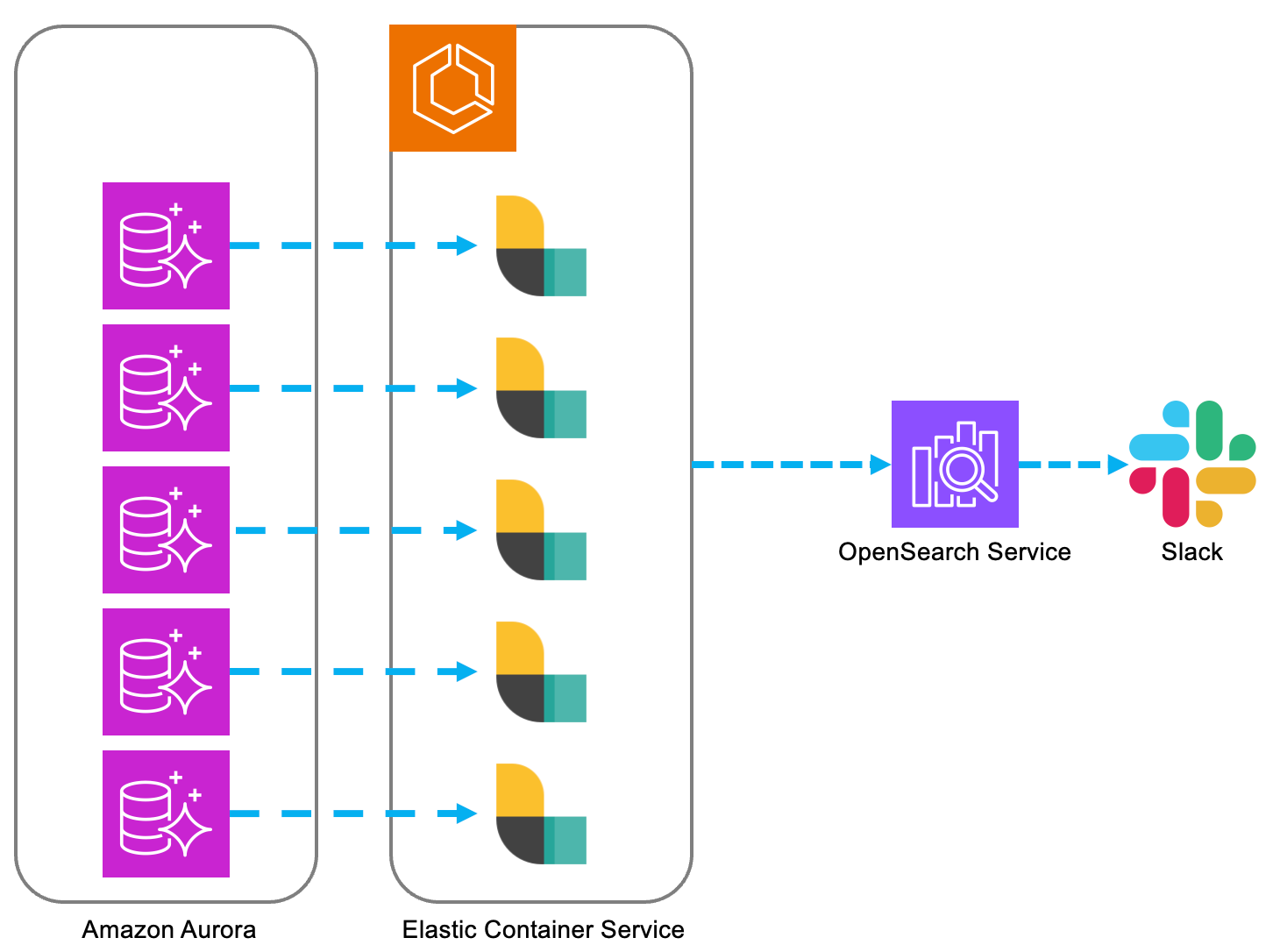
[활용 방안]
Logstash는 일반적으로 Beat나 Lambda 등에서 전달 받은 로그 데이터를 Filter 및 정제하여 Opensearch로 전송하는 데 사용되지만, JDBC 플러그인을 활용하면 관계형 데이터베이스에서 SQL 쿼리를 통해 데이터를 추출하여 OpenSearch로 전달할 수 있습니다. 이를 통해 데이터베이스의 구조화된 데이터도 실시간으로 분석하고 시각화할 수 있으며, 다양한 데이터 소스를 통합하여 모니터링 범위를 넓히고 운영 효율성을 향상시킬 수 있습니다.
OpensSearch와의 연동으로 통합 대시보드를 구성하고 실시간 알림 설정이 가능하여 특정 조건에 부합하는 데이터에 대해서 내부 알림을 통해 현재의 문제 상황을 빠르게 파악할 수 있었습니다.
2. Multi Source Replication을 활용한 RDS 자원 최적화 전략
5월에는 삼쩜삼 RDS 시스템의 모든 자원을 오로지 애플리케이션 서비스에만 할당할 필요가 있었습니다. 고객 서비스를 위한 애플리케이션 서비스 이외의 Anonymous 트랜잭션의 자원 할당과 분석을 위한 집계 쿼리를 최소화해야 했습니다. RDS 시스템의 자원을 전적으로 애플리케이션 서비스에서 사용할 수 있게 할당하고, 불필요한 부하를 줄이기 위해 MySQL의 기능인 Multi Source Replication을 구성하기로 결정하였습니다.
- Multi Source Replication이란?
Multi Source Replication은 AWS RDS MySQL 5.7.44 및 8.0.35 이상 마이너 버전 이상부터 도입된 고급 복제 기능으로, 여러 개의 Master 서버에서 생성되는 데이터를 하나의 Replica 서버로 통합 복제할 수 있도록 지원합니다. 각 Master 서버의 복제 정보는 개별 채널(Channel)로 관리되며, 최대 15개의 Master 서버를 등록하여 동시에 복제할 수 있습니다. 이러한 통합된 데이터베이스 구조는 분석과 분리된 인스턴스 간의 복잡한 데이터 join 기법을 활용할 수 있게 하여, 대용량 데이터 처리와 통합 분석에서 유의미한 인사이트를 도출하는 데 매우 유리합니다.
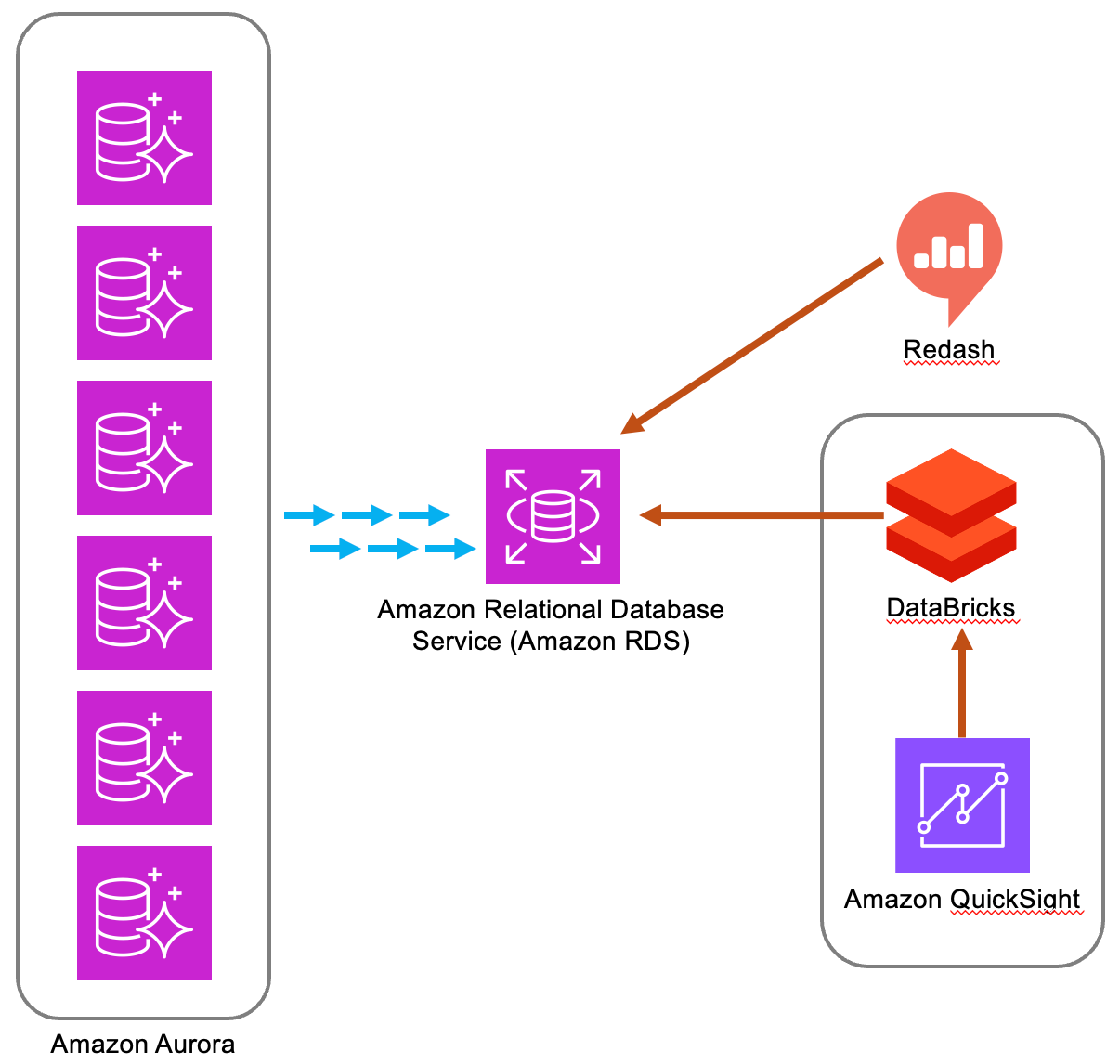
[활용 방안]
서비스의 안정성도 중요하지만, 유입되는 데이터를 분석하는것 또한 필수적입니다. Aurora MySQL이 성능 면에서 장점이 있지만, 현재(24년 10월 기준) Multi Source Replication 기능을 제공하지 않는다는 한계가 있습니다.
RDS에 통합된 데이터는 Databricks로 전송해 대규모 분석 및 머신러닝에 사용하고, Databricks는 QuickSight의소스로 사용되어 비즈니스 지표를 한눈에 확인할 수 있습니다. 또한, 운영 이슈에 대응하기 위한 복잡한 쿼리도 Redash를 통해 운영 환경에 부하를 최소화함으로써, 시스템에 부담을 주지 않고 분석 작업을 원활하게 수행할 수 있었습니다.
3. 커밋 지연 해소를 위한 파라미터 최적화
이전 포스팅
📃
5월을 대비하는 자세:성능 테스트 및 모니터링 시나리오
을 통해 확인할 수 있듯이, 다양한 솔루션을 통해 QA 환경에서 QPS를 증가시키며 추가적인 개선 활동을 수행하였습니다. 그러나 종합소득세 신고가 오픈된 후 얼마 지나지 않아, 테스트 당시 예측했던 유입 이상의 트래픽으로 인해 데이터베이스 지연 현상이 발생했고, Performance Insight를 통해 확인한 결과, aurora_redo_log_flush 이벤트와 MYSQL_BIN_LOG 이벤트가 두드러지게 나타남을 확인할 수 있었습니다.이벤트 분석을 통해 단일 트랜잭션의 빈번한 커밋 지연과 Binary Log 복제를 위한 추가 오퍼레이션으로 인해 일부 RDS에서 성능 저하가 발생하고 있음을 확인할 수 있었습니다.
- aurora_redo_log_flush :
Redo log를 flush 하는 경우 주로 발생하는 이벤트로aurora_redo_log_flush 이벤트가 Performance Insights에서 대부분을 차지하는 것은 주로 높은 쓰기 부하나 스토리지 I/O 병목 등으로 인해 Redo Log Flush 작업이 과도하게 발생하고 있음을 나타냅니다.
- MYSQL_BIN_LOG :
Binary Log 기록 작업이 과도하게 수행되는 경우 발생하는 이벤트로 해당 이벤트 또한 높은 쓰기 부하와 스토리지 I/O 병목과 관련이 있습니다.
어떻게 해결했나?
해당 이슈의 직접적인 원인과 이를 개선할 수 있는 포인트로는 두 개의 파라미터가 있다고 판단했습니다.
- innodb_flush_log_at_trx_commit
- binlog_format
MySQL을 다뤄본 분들이라면 이 파라미터의 변경이 얼마나 신중을 기해야 하는지 잘 아실 것입니다.
결론부터 말씀드리자면, 대량의 트래픽에 대응하기 위해 innodb_flush_log_at_trx_commit파라미터를 0으로 변경하고, 특정 인스턴스의Binary Log를 비활성화하는 선택을 감행했습니다.
먼저, Aurora MySQL 내부 처리와 동작 방식의 기본인 Two-Phase Commit과 위의 파라미터에 대해서 설명하겠습니다.
Two-Phase Commit?
먼저 클라이언트가 Commit을 수행할 때 어떤 과정으로 처리되는지 살펴볼 필요가 있습니다. Redo Log는 인스턴스 Crash와 같은 상황에서 마지막으로 Commit된 데이터를 복구하기 위한 용도로 사용되며, Binary Log는 복제(Replication) 목적으로 사용된다는 점은 잘 알고 계실 겁니다.
Redo Log와 Binary Log 사이에는Two-Phase Commit이라는 원자성을 보장하는 메커니즘이 존재합니다. 쉽게 말해, A 인스턴스(소스)와 B 인스턴스(복제)가 있을 때, A 인스턴스에서 트랜잭션이 발생하여 Redo Log가 작성되고 Binary Log가 복제되는 중에 갑작스러운 Crash가 발생한다면 어떻게 될까요? 만약 Binary Log가 제대로 복제되지 않고 A 인스턴스에만 Redo Log가 적용된다면 데이터 불일치 문제가 발생할 수 있습니다. Two-Phase Commit은 이러한 불일치를 방지하기 위한 프로토콜로, 데이터의 원자성을 보장합니다. ACID의 Atomic(원자성)
Two-Phase Commit은 prepare와 commit이라는 두 단계의 과정을 거칩니다.
Prepare 단계
- 트랜잭션을 준비 상태로 만들고, 모든 참여 스토리지 엔진이 트랜잭션을 커밋할 준비가 되었는지 확인하는 단계
- MySQL은 COMMIT에 대한 요청을 받으면 트랜잭션 코디네이터 역할을 통해 스토리지 엔진과의 조율
- 트랜잭션 준비 단계 호출(MYSQL_BIN_LOG::prepare)
- 각 스토리지 엔진에 리소스를 커밋하고 트랜잭션이 성공하도록 지시(innobase_xa_prepare)
- InnoDB는 트랜잭션이 리두 로그에 완전히 기록되었는지 확인하고 (필요한 경우) 리두 로그 파일을 디스크에 동기화
- MySQL이 충돌하면 InnoDB는 복구 시 진행 중인 트랜잭션을 롤백
Commit 단계
- 모든 참여 스토리지 엔진이 준비 완료 신호를 보내면, 실제로 트랜잭션을 커밋하는 단계
- 스토리지 엔진으로부터 prepare 완료 신호를 받으면 MYSQL_BIN_LOG::commit이 호출되서 바이너리 로그에 트랜잭션 기록
- 커밋하라는 지시를 받음(innobase_commit)
- Redo Log에 Binary Log 정보를 기록하고 commit 수행
- InnoDB는 트랜잭션이 리두 로그에 완전히 기록되었는지 확인하고 (필요한 경우) 리두 로그 파일을 디스크에 동기화
- MySQL은 클라이언트에게 성공 응답(ACK)
위 Two-Phase Commit의 동작 방식에 대한 설명은 Community MySQL 기준의 설명입니다.
Aurora MySQL에서는 트랜잭션이 Redo Log에 기록하는 절차 대신 스토리지로 오프로드 된다는 점이 주요 차이점입니다. 이는 Aurora의 분산 스토리지 시스템과 고성능 아키텍처 덕분에 가능한 방식으로, 데이터를 더욱 효율적으로 관리하고 성능을 향상시킵니다.
innodb_flush_log_at_trx_commit 파라미터
위와 같은 Two Phase Commit 처리 과정 중에서 Redo Log의 데이터를 디스크에 실시간으로 저장할 지 메모리에 보관 후 특정 주기로 저장할 지에 대해 영속성 주기를 제어할 수 있는데 이와 관련한 파라미터를 innodb_flush_log_at_trx_commit(binlog는 sync_binlog 파라미터로 제어) 라고 합니다. 이 설정은 성능과 데이터 내구성 사이에서 중요한 균형을 맞추는 역할을 합니다.
아시다시피, 빈번한 디스크 I/O는 성능에 큰 영향을 미칠 수 있지만, 데이터를 즉시 기록하면 데이터 유실 가능성을 최소화할 수 있습니다. 반대로 디스크 I/O를 줄이면 성능은 개선되지만 데이터 유실 가능성이 커집니다. ACID의 Durability(내구성)
innodb_flush_log_at_trx_commit의 동작 방식은
Community MySQL과 Aurora MySQL에 차이가 있습니다.
일반 Community MySQL 기준 innodb_flush_log_at_trx_commit 동작 방식
1.값 0:
트랜잭션이 커밋될 때 로그 버퍼의 로그가 os 버퍼에 기록되지 않고 1초마다 OS 버퍼에 기록되고 fsync()가 호출되어 디스크의 로그 파일에 기록합니다. 해당 값을 0으로 변경 시 내구성을 보장받을 수 없습니다.
2.값 1 (기본값):
각 트랜잭션 커밋 시 로그를 버퍼에서 로그 파일로 즉시 기록하고, 디스크로 플러시합니다. 이 설정은 가장 안전한 옵션으로, 트랜잭션이 커밋될 때마다 로그가 디스크에 안전하게 기록되므로 서버 충돌 시 데이터 손실 가능성이 최소화됩니다. 하지만 성능이 상대적으로 떨어질 수 있습니다.
3.값 2:
트랜잭션이 커밋되면 로그를 로그 파일로 기록하지만, 디스크로 바로 플러시하지는 않습니다. 대신 1초마다 디스크로 플러시합니다. 이는 값 1과 0의 중간 정도로, 성능과 데이터 안전성 간의 타협을 제공합니다. 이 설정에서는 서버가 다운되었을 때 최대 1초의 로그 손실이 발생할 수 있지만, 그 외의 경우 데이터 손실은 방지할 수 있습니다. 해당 값을 2으로 변경 시 내구성을 보장받을 수 없습니다.
Aurora MySQL 기준 innodb_flush_log_at_trx_commit 동작 방식
트랜잭션이 커밋될 때 데이터베이스 인스턴스에서 로그 파일을 기록하지 않고, 스토리지 계층으로 직접 오프로드 됩니다. 네트워크를 통과하는 유일한 쓰기는 Redo Log 기록이며, 데이터베이스 계층에서는 페이지가 작성되지 않습니다. 또한, Aurora MySQL에서도 내구성 제약을 완화하여 성능을 향상시킬 수 있습니다.
Aurora MySQL 버전 2의 경우:
- innodb_flush_log_at_trx_commit = 0 또는 2 :
데이터베이스는 Redo Log Record가 Aurora 클러스터 볼륨에 기록된다는 확인을 기다리지 않습니다.
- innodb_flush_log_at_trx_commit = 1 :
데이터베이스는 Redo Log Record가 Aurora 클러스터 볼륨에 기록된다는 확인을 기다립니다.
Aurora MySQL 버전 3의 경우:
- innodb_flush_log_at_trx_commit = 0 :
데이터베이스는 Redo Log Record가 Aurora 클러스터 볼륨에 기록된다는 확인을 기다리지 않습니다.
- innodb_flush_log_at_trx_commit = 1 또는 2 :
데이터베이스는 Redo Log Record가 Aurora 클러스터 볼륨에 기록된다는 확인을 기다립니다.
위와 같이 innodb_flush_log_at_trx_commit파라미터 설정 값에 따라 동기/비동기로 인한 성능에 차이가 발생합니다.
비동기 설정으로 운영할 경우, Quorum 획득 여부를 확인하지 않아 예기치 않은 장애 발생 시 Failover 또는 Reboot 과정에서 데이터 손실이 발생할 우려가 있습니다. 따라서 Aurora MySQL 3 버전에서 해당 파라미터를 변경하고 자 하는 경우 innodb_trx_commit_allow_data_loss 값을 1로 설정해야 합니다. 해당 파라미터는 데이터 손실의 위험을 수용하는 것으로 간주되어 innodb_flush_log_at_trx_commit 값의 변경이 가능해집니다.
binlog_format 파라미터
복제 데이터베이스에서 수행되는 비확정적 쿼리에 대한 데이터 일관성을 유지하기 위해 binlog_format을 ROW 방식으로 설정했습니다. 그러나 대량의 트랜잭션으로 인한 Binary Log 복제 과정은 리소스 사용에 추가적인 부정적인 요소가 되었습니다. Binary log 전송 시 Base64 인코딩 과정과 바이너리 로그 기록 과정에서 지연을 초래할 수 있는데, 삼쩜삼 시스템의 수집되는 데이터 자체가 상당히 방대하여 이를 인코딩하고 기록하는 작업이 상당한 시스템 리소스를 소모했습니다. 이에 따라 특정 인스턴스에서는 Reader 인스턴스를 활용하여 데이터 조회 방식을 변경하고 Binary Log를 비활성화하는 방안으로 전환했습니다.
파라미터 변경 후 성능이 개선 되었나?
파라미터를 변경하기 전에 SQL을 그룹화하여 커밋 횟수를 최소화하는 방안을 신중히 검토해야 합니다. 그러나 삼쩜삼의 5월 사례에서는 높은 트래픽과 긴박한 상황 속에서 검증되지 않은 소스 코드를 수정하는 것이 리스크가 크다고 판단하여, 해당 인스턴스의 innodb_flush_log_at_trx_commit 파라미터 값을 0으로 변경하기로 결정하였고, 이를 통해 처리량이 극적으로 향상되었습니다. 그러나 이러한 설정 변경은 데이터 내구성 측면에서 불안정한 트레이드오프 관계이므로, 변경 시 그에 따른 위험성을 명확히 인지하고 신중하게 적용해야 합니다.
Instance Crash 발생 시 대처 방안은 고려하였나?
삼쩜삼 서비스는 MSA를 통해 각 서비스가 개별적으로 분리된 구조로 고객 환급 정보 수집 및 결제와 같은 핵심 서비스들을 독립적으로 운영합니다. 각 서비스 간에는 분산 구조 형태에서의 유입된 데이터를 신뢰할 수 있는 검증 장치가 마련되어 있어 특정 인스턴스에서의 갑작스러운 서비스 중단으로 인한 데이터 유실 위험이 발생하더라도 데이터 검증 절차를 통해 데이터 불일치 문제를 해결할 수 있도록 설계되었습니다.
다시 한번 강조하지만, innodb_flush_log_at_trx_commit 파라미터를 0으로 설정할 경우 1초(혹은 그 이상) 동안 데이터 유실의 가능성이 있습니다. 이는 AWS에서도 권장하지 않으므로 유의해야 합니다. 이러한 변경은 데이터 내구성과 서비스 안정성 간의 균형을 충분히 검토한 후에 적용해야 합니다.
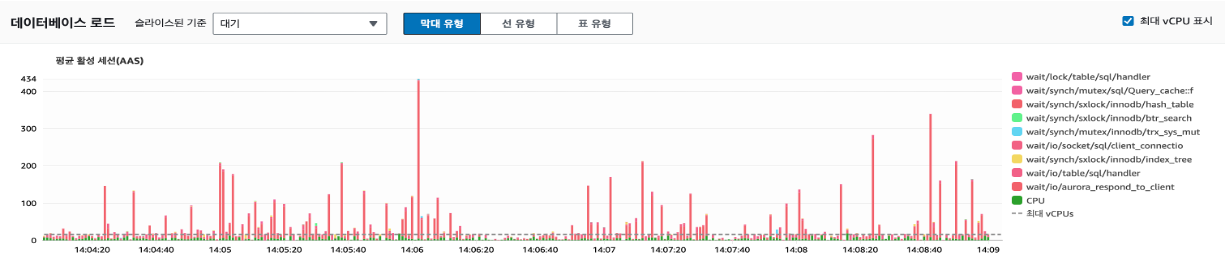
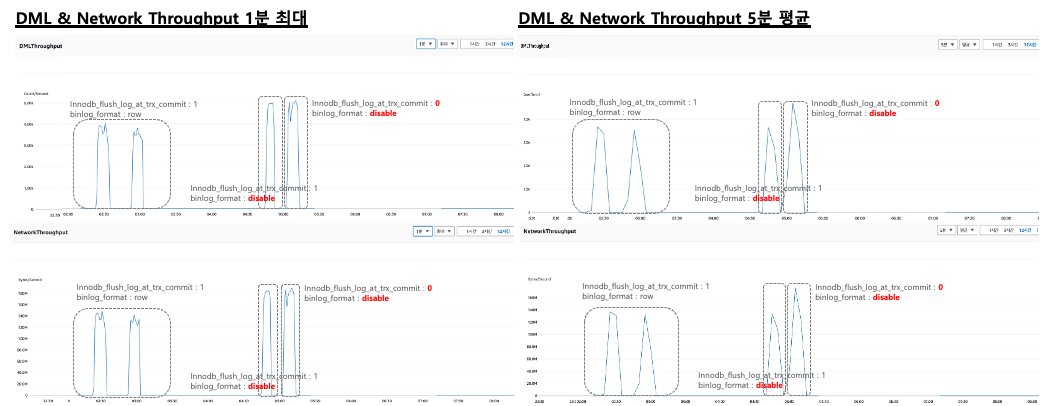
파라미터 변경 후 개선 지표(Performance Insight ASS)
첨부된 워크로드와 메트릭 지표를 바탕으로 시스템 성능 개선 여부를 평가하였으며, 아래 지표는 1,000 TPS 수준의 트래픽을 기준으로 테스트한 결과입니다.
지표 내의 결과로 Wait Event를 동반한 AAS(Average active sessions)의 증가는 성능 지연의 원인이 될 수 있습니다.
- innodb_flush_log_at_trx_commit : 1 & binlog_format : row
Performance Insight 1에서와 같이 최적의 안정성을 보장하는 구성은 aurora_redo_log_flush대기 이벤트가 집중적으로 발생하는 경향을 보였으며, MYSQL_BIN_LOG 이벤트에 대한 발생 빈도 또한 적지 않음을 확인할 수 있었습니다.

- innodb_flush_log_at_trx_commit : 1 & binlog_format : disable
Performance Insight 2는 Binary Log를 비활성화한 지표로 AAS 지표에서 MYSQL_BIN_LOG 이벤트가 제거되면서 모든 워크로드가 커밋을 수반한 트랜잭션과 클라이언트로의 응답에 집중되었습니다. 그에 따라 Network 및 DML 처리량 메트릭의 최대 처리량이 다소 증가한 것을 확인했습니다.

- innodb_flush_log_at_trx_commit : 0 & binlog_format : disable
Performance Insight 3에서는 innodb_flush_log_at_trx_commit 파라미터를 0으로 변경하여 비동기 형태의 Redo Log Logging 처리로 트랜잭션 처리 속도가 향상되고 Logging에 의한 대기가 줄어들어 처리량이 현저히 개선되었습니다. 추가로, Network 및 DML 처리량도 30% 이상 증가한 것을 확인했습니다. aurora_respond_to_client의 대기 현상은 네트워크 대역폭에 대한 대기 현상으로 이는 스케일 업을 통해 해결이 가능합니다.
정리하며..
이번 포스팅에서는 삼쩜삼이 5월의 폭발적인 트래픽 증가에도 안정적인 서비스를 제공하기 위해 어떤 노력을 기울였는지 공유했습니다. 모니터링 시스템 구축부터 부하 분산을 위한 설정, 그리고 발생한 이슈에 대한 신속하고 과감한 대응까지, 삼쩜삼은 서비스의 안정성을 확보하기 위해 최선을 다하고 있습니다.
앞으로도 삼쩜삼은 기술적인 도전에 적극적으로 대응하며, 더욱 견고하고 효율적인 시스템을 구축해 나가겠습니다. 데이터베이스 관리부터 서비스 최적화까지 모든 분야에서 전문성을 발휘하여, 안정적이고 신뢰할 수 있는 서비스를 제공하기 위해 노력하겠습니다.
저희 삼쩜삼은 빠르게 성장하고 변화하는 환경에서 함께 문제를 해결하고 발전해나갈 열정적인 데이터베이스 전문가를 기다리고 있습니다. 데이터베이스 관리 경험과 성능 최적화에 대한 깊은 이해를 가지고 계신 분들의 많은 관심과 지원 부탁드립니다.
📃
채용|삼쩜삼
긴 글 읽어주셔서 감사합니다.
글 | 문성훈
디자인 | 박서영
본 콘텐츠의 저작권은 (주)자비스앤빌런즈에게 있으며, 본 컨텐츠에 대한 무단 전재 및 재배포를 금지합니다